The above DNA sequence is obviously a mutant. But the fact that we can recognize this cryptogram as a nucleotide sequence and diagnose a mutant change illustrates the incredible progress made in the understanding of human biology. Molecular biology is the subspecialty of science devoted to understanding the structure and function of the genome, the full complement of DNA (deoxyribonucleic acid), the macromolecule that contains all the hereditary information.
The Austrian monk Gregor Mendel studied his garden of peas for much of his life at his monastery and was the first to express the principles of heredity in the 1860s. He described dominant and recessive traits and the “laws” of transmission governing the homozygous and heterozygous inheritance of these traits. Mendel’s theories remained unknown until 1900, when they were discovered. Unfortunately, Mendel died 16 years before recognition of his work. But how far we have come in only 150 years, mostly in the last 50 years!
The pairing and splitting of chromosomes at cell division was proposed in 1903, but it was not until 1946 that Edward Tatum and Joshua Lederberg at Yale University demonstrated in bacteria that DNA carried hereditary information. James Watson and Francis Crick, working at the Cavendish Laboratories in Cambridge, proposed in 1953 the structure of DNA by creating a model based on the parameters provided by Maurice Wilkins and Rosalind Franklin obtained with x-ray crystallography. Crick, Watson, and Wilkins received the Nobel Prize in 1962; Franklin died in 1958, and the Nobel Prize is not awarded posthumously.
DNA replication involves many enzyme systems. DNA polymerase was isolated in 1958, and ribonucleic acid (RNA) polymerase in 1960. In 1978, Werner Arber, Hamilton Smith, and Daniel Nathans received the Nobel Prize for their discovery, in the 1960s, of the enzymes for joining or cutting DNA. The use of ligase and restriction endonuclease enzymes permitted the production of recombinant DNA molecules, first accomplished by Paul Berg at Stanford University in 1972.
E.M. Southern of Edinburgh University developed in 1975 the technique to transfer (to blot) DNA from agarose gels onto nitrocellulose filters, enabling DNA fragments to be joined with radiolabeled RNA probes and thus isolated. The cloning of genes or DNA fragments followed the breakthrough discovery that plasmids carrying foreign DNA molecules could be inserted into bacteria, leading to the replication of the foreign DNA.
The genome is the complete set of DNA in an organism. A gene is a contiguous region of DNA that can encode a protein product and contains within its area regulatory sequences that regulate its expression. The study of the functions and interactions of all the genes in the genome required a new designation, “genomics,” coined in 1987 with a journal of that name.
We have entered the age of molecular biology. It won’t be long before endocrine problems will be explained, diagnosed, and treated at the molecular level. Soon the traditional hormone assays will be a medical practice of the past. The power of molecular biology will touch us all, and the many contributions of molecular biology will be perceived throughout this book. But unfortunately, molecular biology has its own language, a language that is almost unintelligible to the uninitiated. We offer this chapter as a guide to molecular medicine.
To begin a clinical book with a chapter on molecular biology and a chapter on biochemistry only serves to emphasize that competent clinical judgment is founded on a groundwork of basic knowledge. On the other hand, clinical practice does not require a technical and sophisticated proficiency in a basic science. The purpose of these first two chapters, therefore, is not to present an intensive course in a basic science, but rather to review the most important principles and information necessary for the development of the physiological and clinical concepts to follow. It is further intended that certain details, which we all have difficulty remembering, will be available in these chapters for reference.
The Chromosomes
We are eukaryotes, organisms with cells having a true nucleus bounded by a nuclear membrane, with multiplication by mitosis. Bacteria are prokaryotes, organisms without a true nucleus, with reproduction by cell division. With the exception of DNA within mitochondria, all of our DNA is packaged in a nucleus surrounded by a nuclear membrane. Mitochondria are believed to be descendants of primitive bacteria engulfed by our ancestors, and they still contain some important genes. Because ova are rich in mitochondria, diseases due to mitochondrial genes (for example, Leber’s optic neuropathy) are transmitted by the mother. The mitochondria in sperm are eliminated during fertilization.
Chromosomes are packages of genetic material, consisting of a DNA molecule (which contains many genes) to which are attached large numbers of proteins that maintain chromosome structure and play a role in gene expression. Human somatic cells contain 46 chromosomes, 22 pairs of autosomes, and one pair of sex chromosomes. All somatic cells are diploid—23 pairs of chromosomes. Only gametes are haploid, with 22 autosome chromosomes and one sex chromosome. The chromosomes vary in size, ranging from 50 million to 250 million base pairs. Chromosome 1 contains the most genes (2,968), and the Y chromosome has the smallest number (231). All contain a pinched portion called a centromere, which divides the chromosome into two arms, the shorter p arm and the longer q arm. The two members of any pair of autosomes are homologous, one homologue derived from each parent. The number of chromosomes does not indicate the level of evolutionary sophistication and complexity; the dog has 78 chromosomes and the carp has 104!
A single gene is a unit of DNA within a chromosome that can be activated to transcribe a specific RNA. The location of a gene on a particular chromosome is designated its locus. Because there are 22 pairs of autosomes, most genes exist in pairs. The pairs are homozygous when similar and heterozygous when dissimilar. Only 2% of the human genome consists of genes that encode protein synthesis. In 1952, Alfred Hershey and Martha Chase confirmed that DNA is the source of genetic transmission. Their report is famously known as the blender experiment, in which labeled DNA in bacteriophages infected bacteria and blender agitation separated the phage particles, demonstrating that the radioactive tracer was present only in the bacterial cells.
The usual human karyotype is an arrangement of the chromosomes into pairs, usually after proteolytic treatment and Giemsa staining to produce characteristic banding patterns, allowing a blueprint useful for location. The staining characteristics divide each arm into regions, and each region into bands that are numbered from the centromere outward. A given point on a chromosome is designated by the following order: chromosome number, arm symbol (p for short arm, q for long arm), region number, and band number. For example, 7q31.1 is the location for the cystic fibrosis gene.
Mitosis
All eukaryotes, from yeasts to humans, undergo similar cell division and multiplication. The process of nuclear division in all somatic cells is called mitosis, during which each chromosome divides into two. For normal growth and development, the entire genomic information must be faithfully reproduced in every cell.
Mitosis consists of the following stages:
Interphase
During this phase, all normal cell activity occurs except active division. It is during this stage that the inactive X chromosome (the Barr body or the sex chromatin) can be seen in female cells.
Prophase
As division begins, the chromosomes condense, and the two chromatids become visible. The nuclear membrane disappears. The centriole is an organelle outside the nucleus that forms the spindles for cell division; the centriole duplicates itself, and the two centrioles migrate to opposite poles of the cell.
Metaphase
The chromosomes migrate to the center of the cell, forming a line designated the equatorial plate. The chromosomes are now maximally condensed. The spindle, microtubules of protein that radiate from the centrioles and attach to the centromeres, is formed.
Anaphase
Division occurs in the longitudinal plane of the centromeres. The two new chromatids move to opposite sides of the cell drawn by contraction of the spindles.
Telophase
Division of the cytoplasm begins in the equatorial plane, ending with the formation of two complete cell membranes. The two groups of chromosomes are surrounded by nuclear membranes forming new nuclei. Each strand of DNA serves as a template, and the DNA content of the cell doubles.
Meiosis
Meiosis is the cell division that forms the gametes, each with a haploid number of chromosomes. Meiosis has two purposes: reduction of the chromosome number and recombination to transmit genetic information. In meiosis I, homologous chromosomes pair and split apart. Meiosis II is similar to mitosis as the already divided chromosomes split and segregate into new cells.
The First Meiotic Division (Meiosis I)
Prophase
Lepotene: Condensation of the chromosomes.
Zygotene: Pairing of homologous chromosomes (synapsis).
Pachytene: Each pair of chromosomes thickens to form four strands. This is the stage in which crossing over or recombination can occur (DNA exchange of homologous segments between two of the four strands). Chiasmata are the places of contact where crossovers occur (and can be visualized). This movement of blocks of DNA is a method for creating genetic diversity. On the other hand, genetic diseases can result from the insertion of sequences during gametogenesis. Transpositional recombination, utilizing enzymes that recognize specific nucleic acid sequences, allows the insertion of a genetic element into any region of a chromosome. This is a method used by viruses (such as the human immunodeficiency virus) to transform host cells.
Diplotene: Longitudinal separation of each chromosome.
Metaphase, Anaphase, and Telophase of Meiosis I
The nuclear membrane disappears, and the chromosomes move to the center of the cell. One member of each pair goes to each pole, and the cells divide. Meiosis I is often referred to as reduction division because each new product now has the haploid chromosome number. It is during the first meiotic division that mendelian inheritance occurs. Crossovers that occur prior to metaphase result in new combinations of genetic material, both favorable and unfavorable.
The Second Meiotic Division (Meiosis II)
The second division follows the first without DNA replication. In the oocyte, meiosis II occurs after fertilization. The end result is the production of four haploid cells.
The Structure and Function of DNA
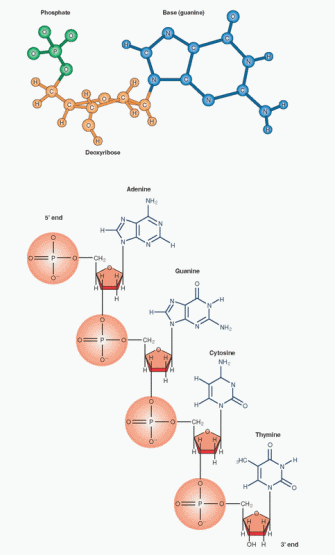
DNA is the material of the gene responsible for coding the genetic message as transmitted through specific proteins. Thus, it is the most important molecule of life and the fundamental mechanism for evolution. Genes are segments of DNA that code for specific proteins, together with flanking and intervening sequences that serve controlling and regulating functions. Each molecule of DNA has a deoxyribose backbone, identical repeating groups of deoxyribose sugar linked through phosphodiester bonds. Each deoxyribose is attached in order (giving individuality and specificity) to one of four nucleic acids, the nuclear bases:
A purine—adenine or guanine.
A pyrimidine—thymine or cytosine.
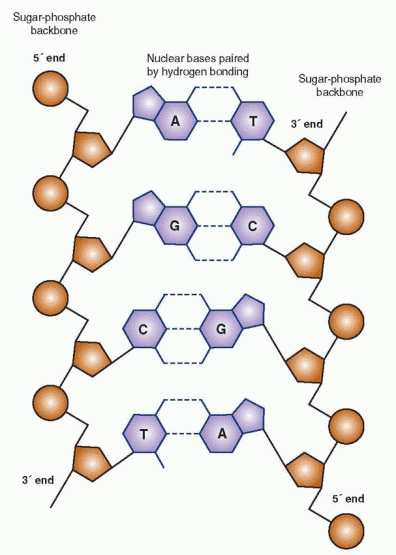
A nucleotide is the basic building block of DNA. It consists of three major components: the deoxyribose sugar, a phosphate group, and a nucleic acid base. The phosphate-sugar linkages are asymmetric; the phosphorus is linked to the 5-carbon of one sugar and to the 3-carbon of the following sugar. Thus, one end is the 5′ (5 prime) end and the other the 3′ (3 prime) end. By convention, DNA and its nuclear acid sequences are written from left to right, from the 5′ end to the 3′ end, the direction of the transcription process. The 5′ end leads to the formation of the amino end of the protein; the 3′ end forms the carboxy end of the protein.
DNA consists of two deoxyribose strands twisted around each other clockwise in a double helix, with the nucleic acids on the inside and the nuclear bases paired by hydrogen bonding, adenine with thymine and cytosine with guanine. RNA differs from DNA in that it is single stranded, its sugar moiety is ribose, and it substitutes uracil for thymine. Phoebus Levene, a Russian immigrant to the United States, working at the Rockefeller Institute of Medical Research from 1905 until he died in 1940, identified the components of DNA (discovering and naming the ribose and deoxyribose sugars) and was the first to suggest the nucleotide structure, research that provided the foundation for the later delineation of the DNA’s significance.
How can a cell’s DNA, which stretched out measures nearly 2m long, fit into a cell? Watson and Crick figured this out when they proposed a tightly coiled two-stranded helix, the double helix. Like the centimeter is a measure of length, the base pair (bp) is the unit of measure for DNA. The base pair is either adenine-guanine or cytosine-thymine, the nucleic acid of one chain paired with the facing nucleic acid of the other chain. A fragment of DNA, therefore, is measured by the number of base pairs, e.g., a 4,800-bp fragment (a 4.8 kb fragment). It is estimated that we have nearly 3 billion bp of DNA, only a small portion of which actually codes out for proteins.
DNA does not exist within the cell as a naked molecule. The nucleotide chains wind about a core of proteins (histones) to form a nucleosome. The nucleosomes become condensed into many bands, the bands that are recognized in karyotype preparations. This condensation is another important mechanism for packing the long DNA structure into a cell. Many other proteins are associated with DNA, important for both structure and function.
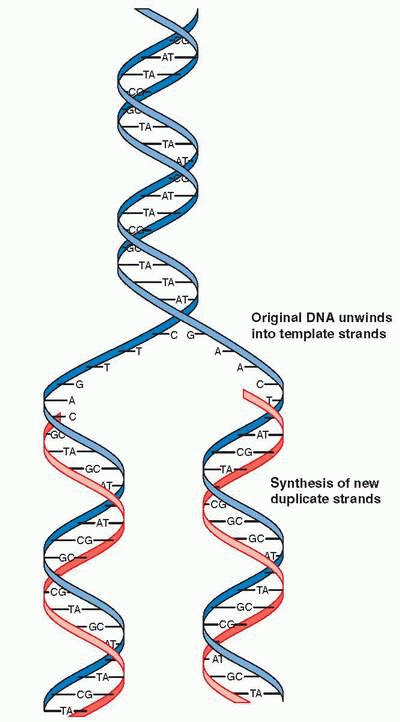
The process of DNA replication begins with a separation of the double-stranded DNA helix, initiated at multiple steps by enzyme action. As the original DNA unwinds into template strands, DNA polymerase catalyzes the synthesis of new duplicate strands, which re-form a double helix with each of the original strands (this is called replication). Each daughter molecule, therefore, contains one of the parental strands. It is estimated that the original DNA molecule present in the fertilized zygote must be copied approximately 1015 times during the course of a human lifetime. Rapidity and accuracy are essential. By combining precision with error correction systems, errors that affect the function of the gene’s protein are surprisingly rare.
The 20 Amino Acids in Proteins
Amino Acid
Three-Letter Abbreviation
Single-Letter Code
Glycine
Gly
G
Alanine
Ala
A
Valine
Val
V
Isoleucine
Ile
I
Leucine
Leu
L
Serine
Ser
S
Threonine
Thr
T
Proline
Pro
P
Aspartic acid
Asp
D
Glutamic acid
Glu
E
Lysine
Lys
K
Arginine
Arg
R
Asparagine
Asn
N
Glutamine
Gln
Q
Cysteine
Cys
C
Methionine
Met
M
Tryptophan
Trp
W
Phenylalanine
Phe
F
Tyrosine
Tyr
Y
Histidine
His
H
The homeobox is a DNA sequence, highly conserved throughout evolution, that encodes a series of 60 amino acids, called a homeodomain. Homeodomain protein products function as transcription factors by binding to DNA. The homeobox influences specific tissue functions that are critical for growth and development of the embryo.
The Human Genome
The genome for each species consists of the complete set of DNA sequences on all the chromosomes. There are nearly 3 billion bps in each haploid human genome; in the double-stranded helix DNA, there are 6 billion nucleotides, and there are an estimated 20,000 to 25,000 genes, the smallest functional unit of inherited information. Genes account for only about 2% of human DNA. Although enormously complex at first glance, the entire genetic language is written with only four letters: A, C, G, and T (U in RNA). Furthermore, the language is limited to only three-letter words, codons. Finally, the entire genetic message is fragmented into the 23 pairs of chromosomes. With four nucleotides, reading groups of three, there are 64 possible combinations. Essentially all living organisms use this code. The genome changes only by new combinations derived from parents or by mutation.
The mRNA Genetic Code
Second Position
First Position (5′ end)
U
C
A
G
Third Position (3′ end)
U
Phe
Ser
Tyr
Cys
U
Phe
Ser
Tyr
Cys
C
Leu
Ser
Stop
Stop
A
Leu
Ser
Stop
Trp
G
C
Leu
Pro
His
Arg
U
Leu
Pro
His
Arg
C
Leu
Pro
Gln
Arg
A
Leu
Pro
Gln
Arg
G
A
Ile
Thr
Asn
Ser
U
Ile
Thr
Asn
Ser
C
Ile
Thr
Lys
Arg
A
Met
Thr
Lys
Arg
G
G
Val
Ala
Asp
Gly
U
Val
Ala
Asp
Gly
C
Val
Ala
Glu
Gly
A
Val
Ala
glu
Gly
G
Reading across the first row of the table, the codon UUU specifies Phenylalanine, the codon UCU specifies Serine, the codon UAU specifies Tyrosine, and the codon UGU specifies Cysteine. UAA, UAG, and UGA are stop codons.
Only gold members can continue reading. Log In or Register to continue