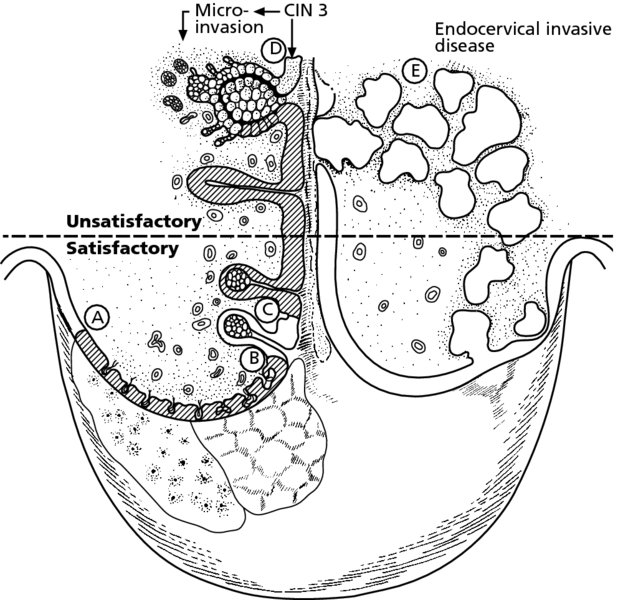
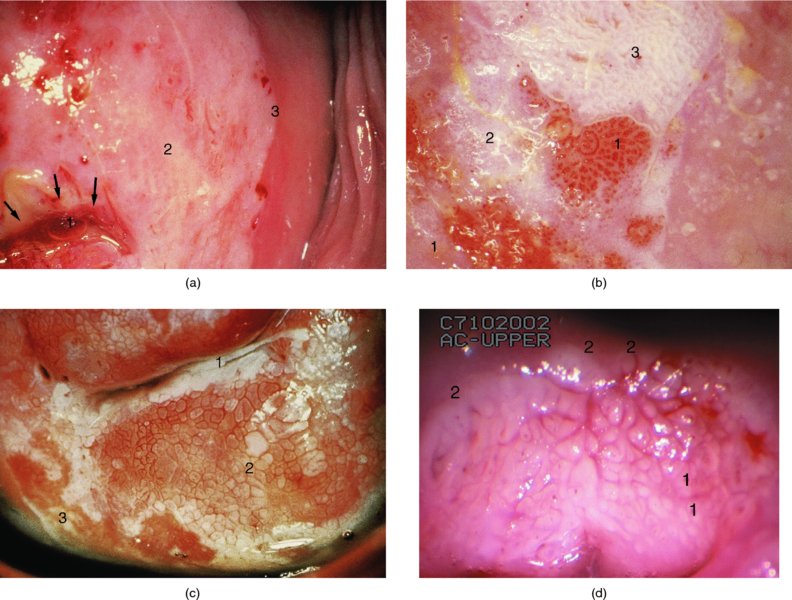
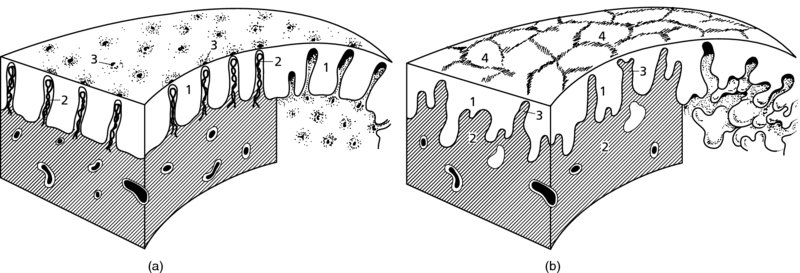
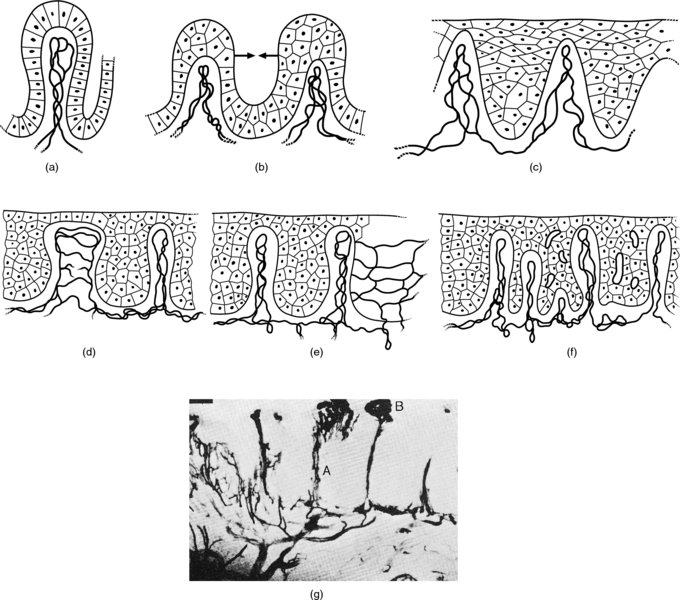
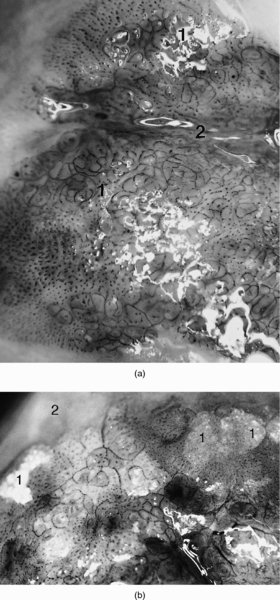
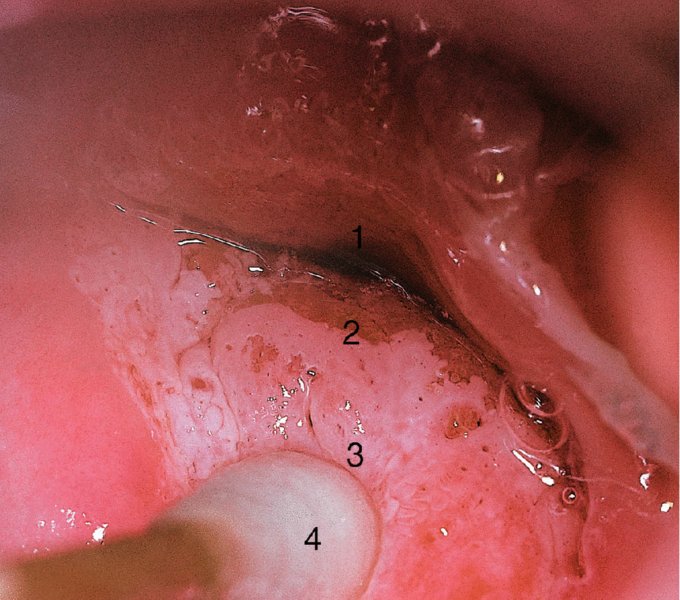
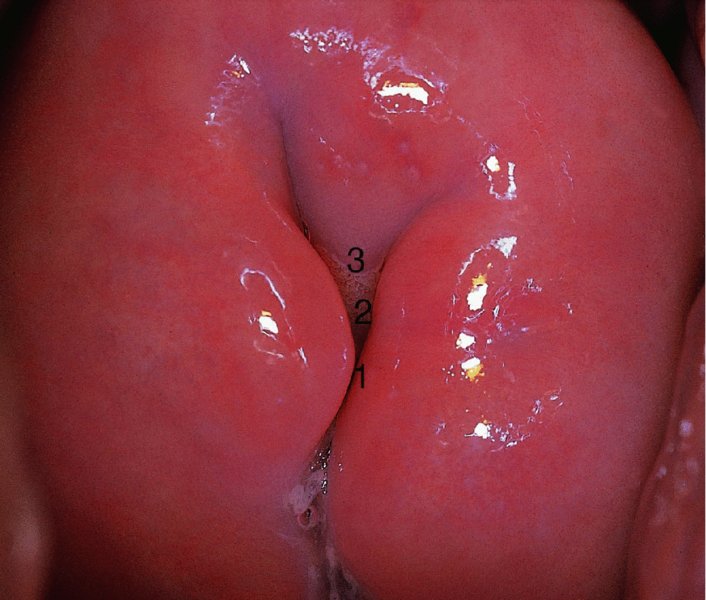
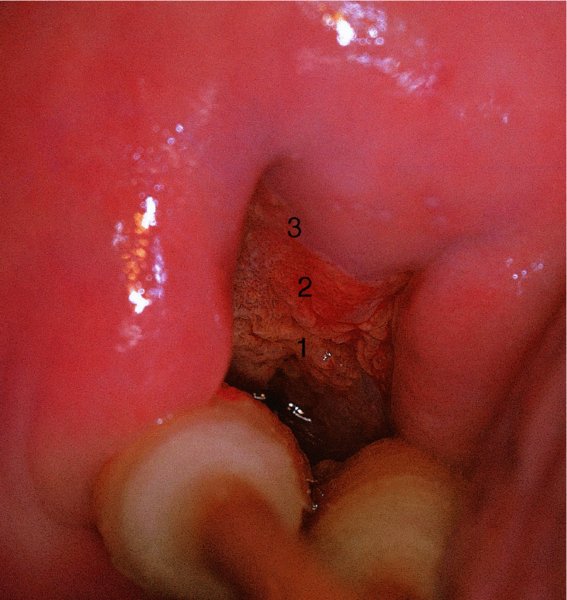
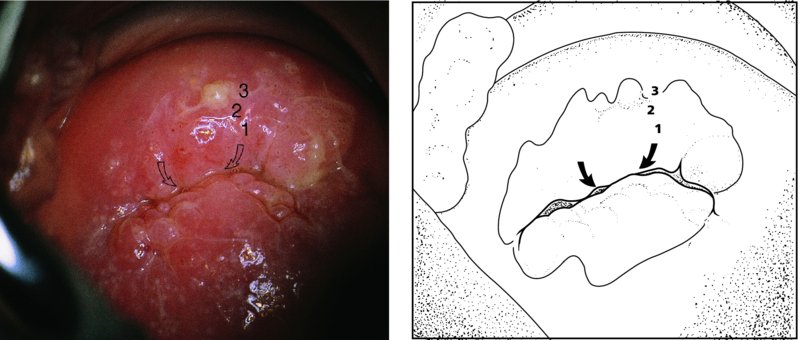
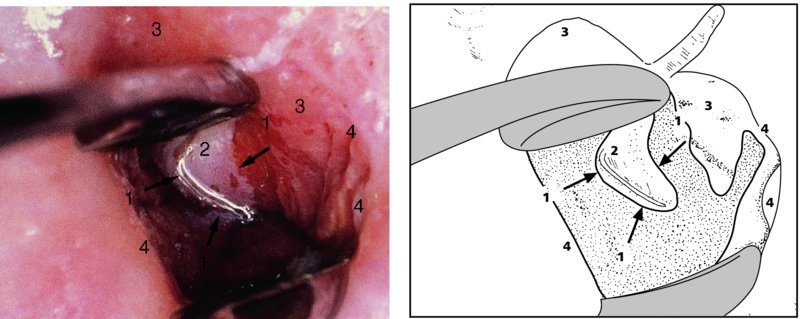
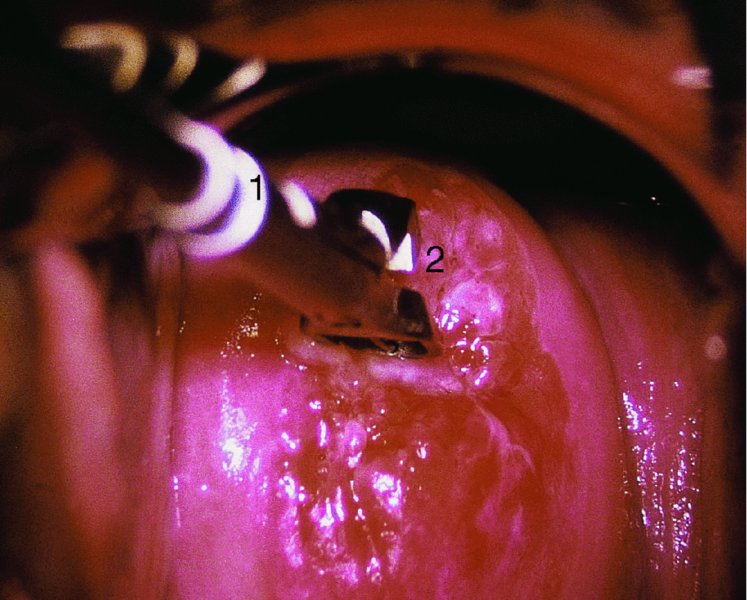
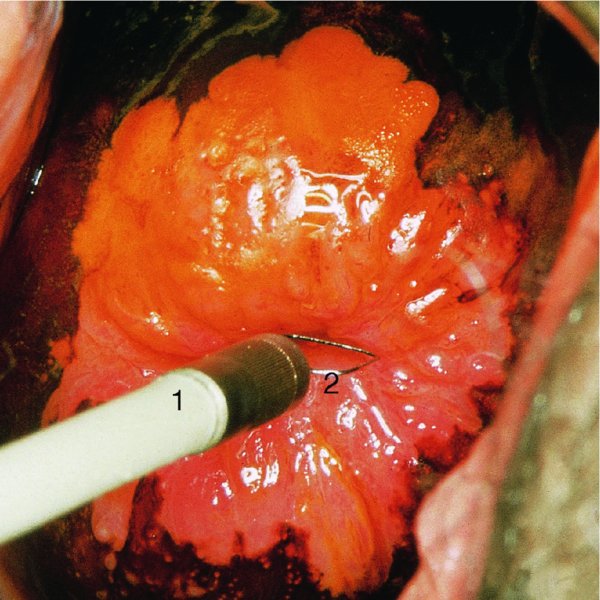
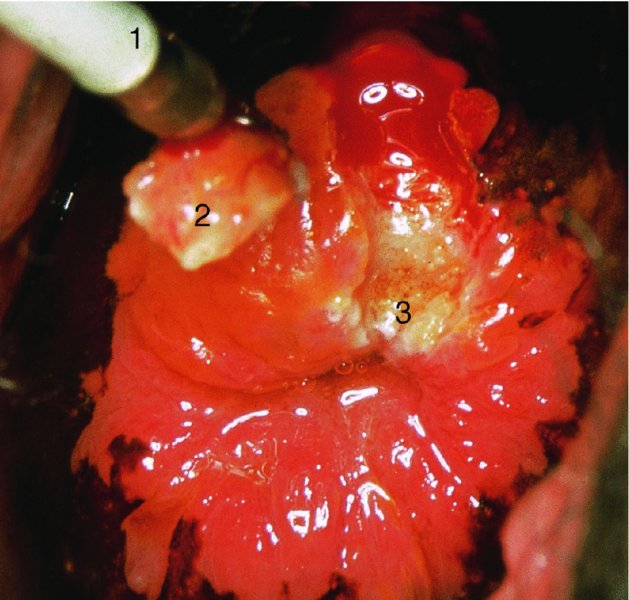
CHAPTER 6 In the diagnosis of cervical precancer the four modalities, namely cytology, human papillomavirus (HPV)-related biomarkers, colposcopy, and histopathology, are interlinked and complementary. They must be used by the clinician, who should understand and be aware of the advantages and disadvantages of each technique. The realization that there is a variable malignant potential in many cervical epithelial lesions has been translated into a more realistic classification of these lesions by the use of the four modalities. Each has now rationalized the classification into lesions that are at high or low risk of progression to malignancy. Histopathologists reserve the term high-grade cervical intraepithelial neoplasia (CIN) for those lesions that are thought to be true precursors of invasive cancer. Likewise, the experienced colposcopist is able to differentiate lesions into those that are at either high or low risk of progression to malignancy, while cytologists using revised classifications also stress the cellular changes that indicate either a low- or high-grade squamous intraepithelial lesion (LSIL or HSIL, respectively). Various biomarkers can now differentiate cervical lesions with progression potentiality from low-grade lesions and which are likely to regress back to normal. The cytologic assessment and more recently the HPV status of the cervix provides the important link between the gynecologist and the patient. In most screening programs, it is the cervical smear and in the future the HPV characteristics of the cervical sample that provide the clues to the presence of neoplastic abnormalities within the cervix and lower genital tract. As a result of this information the clinician is able to select those patients who will need further diagnostic triage assessment, that is, by colposcopy. The presence of an abnormal smear should alert the clinician to the fact that there may well be a precancerous lesion in the cervical epithelium. At present, a number of findings within a cervical smear should dictate either referral of a woman to a specialist clinic where colposcopy can be performed or examination of the cervix by the practitioner. The indications for referral for colposcopic examination of the cervix are as follows: Obviously, any clinical suspicion of invasive cancer on the cervix would qualify the patient for colposcopic assessment. The presence of contact bleeding of the cervix, of intermenstrual and irregular blood-stained vaginal discharge, or of a suspicious lesion of the cervix, such as a hypertrophied transformation zone, should immediately alert the clinician to the possible presence of cervical malignancy. The types of abnormal smear that qualify the patient for a colposcopic examination were listed in the preceding section. Once the patient has been recommended for an examination there are a number of conditions that must be satisfied by the colposcopist before a satisfactory opinion can be given on the nature of the lesion. It is important that the clinician: Figure 6.1 shows the varied topographic arrangements of the major pathologic lesions within the cervix and its epithelium that give rise to abnormal (atypical) colposcopic findings. The important features of these lesions that are noted on the colposcopic examination can be seen. Figure 6.1 A diagrammatic representation of the cervix showing the different topographic arrangements of the pathologic epithelia that may be examined by colposcopy. (A) and (B) An ectocervical area of epithelial abnormality with specific morphologic features and associated abnormal vascularity giving rise to the characteristic punctation and mosaic appearances that are visible colposcopically. (C) (shaded) A cervical intraepithelial neoplasia (CIN) lesion extends into the endocervix; the upper limit is not visible. Continuation of the lesion above a certain line (dashed horizontal line) signifies the border between a satisfactory and, in this case, unsatisfactory colposcopic examination (the upper extent of the lesion is not visible). (D) (stippled) An endocervical lesion such as the one shown here may be purely an extension of major intraepithelial disease, such as CIN3, or may occur in conjunction with an early invasive cancer, i.e., microinvasive carcinoma. Special techniques are needed to determine the exact extent of this lesion within the endocervix. (E) Very occasionally, endocervical invasive carcinoma may present initially in this area within the endocervical canal. Examination is required to ensure that such lesions as this are not missed; the presentation would be that of an unsatisfactory colposcopic examination. Colposcopy with associated biopsy is described as the “gold standard” for the diagnosis of cervical precancer. In the USA approximately 50 million Papanicolaou smears are performed annually; of these, approximately 2.5 million (5%) show evidence of low-grade abnormalities. The usual management of these low-grade lesions is a combination of both colposcopy and directed biopsy. There have been very few objective analyses of the efficacy or performance of colposcopy. Colposcopy has a very acceptable sensitivity, specificity, and positive predictive value. A meta-analysis showed that the sensitivity of diagnostic colposcopy was high, ranging between 87% and 99%, but its specificity was lower. This has given rise to the concept that, to improve the efficacy of colposcopy, multiple biopsies must be taken. In the diagnosis of high-grade epithelial lesions there were characteristic distinguishing features that allowed them to be better separated from low-grade lesions, and it appeared that this differentiation was easier to perform than separating low-grade lesions from physiologic cervical epithelium. Although criticism of colposcopy exists, it would seem as though the training of the colposcopist is of paramount importance. For example, comparison is made between the finding in the large Atypical Squamous Cells of Undetermined Significance/Low-grade Squamous Intraepithelial Lesion Triage Study (ALTS) in the USA in the mid-1990s of a large screening population in which colposcopy was performed by clinicians with variable experience and those from an equally large British study in which colposcopy was also employed. In the ALTS a rate of 11.5% for CIN2+ existed initially in those who were eventually found with normal colposcopy compared with only 5.2% in the British study. Indeed, in the British study 94.6% of CIN2+ cases were detected at the original colposcopy compared with only 72.3% in the ALTS group. What is the explanation ? First, in the British system the setting for the risk of missing high-grade disease by colposcopy appears to be much lower than in the ALTS. Second, in the British colposcopy system there is a comprehensive training system that guarantees a high standard of training in colposcopy. Last, the British colposcopy service is subject to strict quality control. The colposcopic morphology of the abnormal (atypical) epithelium harboring the cervical precancerous lesion (or CIN) is dependent on a number of factors. These include: When acetic acid is applied to this epithelium certain changes occur within the cellular proteins. These biochemical changes are transient and reversible and can be seen through the colposcope as a whitening or opaqueness occurring within the visible epithelium. The normal epithelium washed with acetic acid remains unchanged, retaining its translucent pink color. When iodine solution is applied to normal tissue, a brownish stain develops owing to the inherent glycogen content. This is the so-called iodine-positive test or positive Schiller’s test. Other tissue types have variable staining reactions and these will be discussed below. Before acetic acid is applied, the normal translucent squamous epithelium reflects the underlying vascular connective tissue. Once acetic acid has been applied and coagulation of the cellular proteins has occurred, the squamous epithelium becomes progressively opaque, initially developing a flat dull appearance that masks the reflection of the underlying connective tissue (see Figures 3.1, 3.2). If there is a thickened or extremely cellular epithelium, as is found in the major-grade CIN lesions (i.e., CIN 3), then the opacity is such that the lesion becomes progressively more white. Also, a sharp line develops between the normal and abnormal (atypical) epithelium with the application of acetic acid. Because there is a lack of glycogen in this tissue, the application of iodine will produce a relative whiteness within the epithelium; this forms the basis for the iodine or Schiller’s test. In normal epithelium there are minimal amounts of protein and large amounts of glycogen, especially within the cytoplasm, while in the abnormal (atypical) epithelium there is protein in the cell membrane, nuclei, and cytoplasm, but very little glycogen. In lesions where there are significant amounts of both protein and glycogen, as is found in the minor-grade CIN lesions, acetic acid will produce only a slight whitening and opacity of the epithelium. Likewise, the application of iodine will show a weak and unequal staining. Acetowhite changes are the most important of all the colposcopic features because they are associated with the spectrum of change from normal epithelium (i.e., immature squamous metaplasia) to cancer. It is therefore important that the physiologic and minor pathologic changes are differentiated from more severe neoplastic alterations (i.e., CIN/cancer) within the epithelium. The degree of acetowhiteness is one of four specific colposcopic features that differentiate the normal from the abnormal (atypical) cervical epithelium. The three other features are: The margins of the abnormal (atypical) cervical epithelium are graded according to a number of features that include the sharpness, shape and thickness of the border and the presence of internal margins. In more severe or high-grade epithelial abnormalities (CIN), as seen in Figures 6.2a and 6.16, the margins exhibit a distinct raised edge (Figure 6.2a, (3)). These types of high-grade lesions may be located within a larger low-grade lesion and have an internal margin or demarcation. This is seen in relation to area 1 and its surrounding tissues and in areas 2 and 3 in Figure 6.2b. In low-grade or minor lesions, the margins are usually described as irregular, feathered, angular, or geographic and indistinct. “Satellite” lesions or exophytic micropapilliferous condyloma-like lesions are similarly low grade. The contour of these edges or margins is clearly seen in Figures 6.59–6.62 and 6.101. Figure 6.2 (a) Acetowhite change within the transformation zone showing the upper limit of the process (arrow) within the endocervical canal (1). The thick, abnormal (atypical) epithelium at (2) has stained extremely white and a sharp border (3) indicates the original squamocolumnar junction. (b) Punctation (1) seen after the application of acetic acid with acetowhiteness at (2) and changes suggestive of the presence of human papillomavirus at (3); this latter tissue also shows acetowhiteness. (c) A mosaic vascular pattern showing coarse mosaic epithelium within a wide field of acetowhiteness that extends into the endocervical canal at (1). The mosaic pattern is at (2) and the sharp squamocolumnar junction is outlined at (3). Note the variation in intercapillary distance within the mosaic field; this indicates different grades of precancerous change. (d) Dense acetowhite epithelium with a coarse mosaic pattern is obvious. Wide intercapillary distances exist as well as the presence of tufted glands at (1). The original squamocolumnar junction is at (2) and the new squamocolumnar junction within the canal cannot be seen. The stereoscopic magnification produced by colposcopy enables the surface contour to be visualized and can be described as smooth, papillary, nodular, uneven, or even ulcerated. For instance, native squamous epithelium has a smooth surface, while columnar epithelium is recognized as grape-like and papillary (see Figure 4.6a). High-grade CIN (Figure 6.16), and particularly CIN3 and early invasion, give an uneven, slightly elevated surface (Figure 6.16), whereas the frankly invasive lesions have a nodular or polypoid surface (Figure 6.109) that finally develops to an ulcerated or exophytic growth pattern. The colposcopic signs in relation to degrees of acetowhiteness, margins, vessel formation, and iodine staining have been used by a number of authors to differentiate low- and high-grade epithelial lesions and thereby to establish a colposcopic index grading system (i.e., the Reid index or Swede score). These will be described later. Often in epithelium stained with acetic acid intraepithelial vessels will be absent, but sometimes the appearance of these vascular elements is sufficiently characteristic to warrant names being given to the abnormal appearance. There are two vascular patterns found within the abnormal epithelium: punctation and mosaic. Combinations of these two patterns may also exist. When the capillaries are studded throughout the epithelium and are seen end-on as red points, the term punctation is used. Equally common is the appearance of capillaries in a wall-like structure that subdivides blocks of tissues in a honeycomb fashion; this is the so-called mosaic pattern. Punctation is easily recognized by dilated, often twisted, and irregular terminating vessels that are of a hairpin type and can be elongated and arranged in a prominent punctate pattern (Figures 6.2b, 6.3a, 6.5). The area is usually well defined so that a sharp line separates the normal from the abnormal epithelium (Figure 6.2b). This pattern of punctation is also seen when there is inflammation of the tissue, especially in relation to trichomonal infection and cervicitis. The dilated hairpin capillaries are usually diffuse across the ectocervix, with the actual capillaries lying close together with no sharp separation line between normal and abnormal tissue. Figure 6.3 (a) Representation of the punctate areas seen colposcopically. Between the epithelial buds (1), there is a vascular bundle (2) that nearly reaches the surface where the squamous epithelium is very thin. This allows the vessels to be seen through the surface (3). Vessels within the stromal connective tissue can be easily seen. (b) Representation of the mosaic pattern with the epithelial buds (1) protruding into and ramifying within the stromal connective tissue (2). The capillaries between these epithelial buds (3) come close to the surface and where the epithelium is thin the mosaic pattern is easily seen (4). Figure 6.4 (a–g) Development of atypical squamous metaplasia. For an unknown reason the metaplastic epithelium starts to grow in buds or blocks, while the central vascular network, for example the villi of the columnar epithelium, remains as punctate or mosaic vessels that extend close to the surface of the epithelium. The mosaic vessel form basket-like structures around the blocks of neoplastic cells. (g) A photomicrograph (angiography using alkaline phosphatase, 125 mm section) demonstrating this effect. It shows coiled intraepithelial capillaries at A with numerous subepithelial vessels ending in a capillary network beneath the epithelium at B. Adapted from Kolstad P, Stafl A. Atlas of Colposcopy, 3rd edn. Edinburgh, UK: Churchill Livingstone, 1982, p. 58. Figure 6.5 Punctation (1) within a field of intraepithelial neoplasia. This widespread and variable field of punctuated vessels indicates the presence of various degrees of high- and low-grade cervical intraepithelial neoplasia (CIN). Capillaries toward the center of the field are more spaced, indicating a higher degree of CIN than in the capillaries at the periphery, which are more closely spaced and indicate a lesser degree of abnormality. In the mosaic pattern the capillaries are arranged parallel to the surface, forming a quasi-pavement-like appearance (Figures 6.2c,d, 6.3b). The vessels enclose a vascular field that ranges from small to large and may be regular or irregular in shape (Figure 6.2c). The vessels themselves may have a complex outline. Histologically, the abnormal (atypical) epithelium forms buds that push, and sometimes ramify, into the connective tissues but are held in place by the basement membrane. When acetic acid is applied to the tissue, a pattern of small white cobblestones is produced, each corresponding to an epithelial bud that is surrounded by a red margin that corresponds to the above-described blood vessels. If iodine is applied to the tissue, the abnormal (atypical) squamous epithelium becomes straw-colored and the mosaic pattern disappears. One of the mechanisms that has been proposed for the formation of punctation and mosaic epithelium is that, during the development of squamous metaplasia within the exposed columnar epithelium, exposure to a mutagenic agent results in the production of an atypical metaplastic process. In atypical metaplasia the individual stromal papillae do not coalesce or fuse but the metaplastic squamous epithelium completely fill the clefts and folds of the ectocervical columnar epithelium (Figure 6.4a–f). The central vascular networks of grape-like papillae (Figure 6.4a) of the columnar epithelium remain as thick stromal papillae (Figure 6.4b) surrounded by metaplastic epithelium. At a later stage of development the blood supply of the surface epithelium is probably greater than that found in the normal transformation zone. Any application of acetic acid will show the stromal papillae as red fields surrounded by “white strands” of metaplastic epithelium (Figure 6.4c). As atypical metaplastic development proceeds, it is characterized by increased proliferative activity of the epithelium within the clefts, with the resulting compression of the stromal papillae (Figure 6.4d–f). The vessels within these papillae undergo dilatation and proliferation near the surface (Figure 6.4d,e) or tend to form a basket-like vascular network around buds of abnormal (atypical) epithelium (Figure 6.4d). As seen in Figure 6.4, a lesion derived from these changes would appear colposcopically as punctations and/or a mosaic structure (Figure 6.4d). The development of both mosaic and punctation patterns within the transformation zone is basically similar and so it is not surprising that both can be found in the same lesion, as shown in Figure 6.6. Figure 6.6 Punctation and mosaic patterns exist in this field of cervical intraepithelial neoplasia (CIN). The endocervical canal is at (1) and areas of punctation exist at (2), but these vary and the more widely spaced capillaries indicate a higher grade of CIN. The same applies in area (3), where there is variation in the intercapillary distance within the mosaic epithelium. In area (4) thick, white epithelium surrounds some gland openings. This lesion comprised essentially low-grade CIN (around (2)) with small areas (around (3) and (4)) of high-grade CIN. Another important feature when assessing an area of mosaic or punctation is intercapillary distance. This refers to the distance between the corresponding parts of two adjacent vessels or to the diameter of fields delineated by network or mosaic-like vessels. In native squamous epithelium the intercapillary distance averages approximately 100 mm but in preinvasive, and certainly invasive, cancer this increases as the malign nature of the lesion increases. However, not all punctation and mosaic patterns are abnormal. This emphasis on abnormal vascular patterns has often led to inexperienced colposcopists overlooking a more severely atypical area, as the majority of squamous intraepithelial lesions do not have colposcopically atypical vessels. Punctation and mosaic may also be found in normal epithelium. Mosaicism and punctation can also be found in association with acanthotic epithelium, which is a characteristic of the congenital transformation zone. In this situation there is extensive budding and branching of the dermal papillae and the interdigitating epithelial pegs (see Figures 4.44b,c, 4.50). The intercapillary distances are variable but are usually not excessive, which helps its distinction from a neoplastic lesion. In the latter the epithelial pegs (i.e., of CIN) are wider, thicker, and more irregular. Seventy percent of mosaic and punctation patterns can be associated with benign acanthotic epithelium and 30% with CIN. In contrast, within the transformation zone, these patterns correspond to CIN in 80% and to benign acanthotic epithelium in 20% of cases. However, most authors would contend that CIN is restricted to the transformation zone, bounded by the original squamocolumnar junction and the new squamocolumnar junction. Atypical vessels have a characteristic appearance and are associated with significant major pathologic changes within the epithelium (Figure 6.7a–c). They are described as terminal vessels and are characterized by irregularities in shape, course, density, caliber, and spatial arrangement, where the intercapillary distance is larger than that seen between the vessels of the original squamous epithelium. In many cases the vascular pattern may be so irregular that it is indeed impossible to determine whether the pattern is either punctation or mosaic. The atypical vessels may be found in areas where typical punctation and/or mosaic patterns exist. It would seem that by proliferation of these vessels the areas of ordinary mosaic and punctated changes will eventually develop into areas of atypical vessels. When an irregular pattern such as this develops within fields of punctation and mosaic it may represent the first signs of early invasion, and usually involves the most superficial parts of the basket-like atypical mosaic vessels starting to proliferate into the adjacent mosaic fields. Meanwhile, the punctation vessels can be seen with the tops of their loops running parallel with the surface, covered by only a few cell layers. These horizontal and superficial vessels are distinctive and may be indicative of early stromal invasion. Figure 6.7 (a) Atypical vessels seen in a very invasive squamous carcinoma involving both endo- (1) and ectocervix (2). There is a combination of network-like and branched atypical vessels (2). The network-like vessels have an irregular course with sharp bends and show color variation. Branched vessels also have an irregular pattern, and such branches show a characteristic decrease in diameter. Original squamous epithelium is at (3). (b) Very atypical branching of vessels within the endocervix in an early invasive squamous carcinoma. The gross variation in caliber and irregularity is easily seen by comparison with the physiologic branched vessels in Figures 6.8 and 6.9. (c) Very irregular and atypical vessels with a corkscrew appearance based on an original branching or network pattern and present in an early invasive carcinoma. Before acetic acid is applied these atypical vessels are visible through the translucent gel formed by the epithelial buds; formation of such gel is characteristic of early invasive carcinoma. The vascular network varies in density in different parts of the tumor and sometimes large vascular loops can be seen to have emerged from the stroma, run over the surface, and then descended into the deeper parts. These large vessels often project considerably above the surface, while the smaller ones are narrow and have a corkscrew configuration. Initially, it seems as though the intercapillary distance within the precancerous tissue is reduced, but as the lesion becomes more malign relatively larger avascular areas are formed. The malign cells are nourished by atypical branches or network-like vessels which, in turn, endow the surface tissue with a coarse meshwork appearance. The atypical vessels branching into these avascular areas show great variation in size, shape, and course; it would seem that the vascular growth has to keep pace with the rapid growth of the malignant cells (Figure 6.7b,c). Sometimes, the growth of these latter cells is so rapid that the blood supply cannot keep up and necrosis develops. Atypical branch vessels never form the fine network seen in the branch vessels of the transformation zone (Figures 6.8, 6.9). They do not have the regular tree-like pattern with subsequent decrease in the diameter of single branches as is found in physiologic tissues. Figure 6.9 Epithelial vascularity is best demonstrated using the technique of saline colposcopy, in which the cervical surface is painted with physiologic saline with a green filter. The blood vessels become obvious and easier to see after the saline has been applied. However, when 3–5% acetic acid is used there is an immediate acetowhitening of the squamous component of the epithelium with a dramatic reduction in the clarity of the vascular pattern. With the green filter in situ, and following the application of saline, the red blood vessels appear as dark objects and become much more readily visible. A number of major-grade CINs and early invasive lesions are featured in Figures 6.10–6.13. Figure 6.10 This lesion was shown histologically to be a cervical intraepithelial neoplasia 3 with early microinvasion. It has three features that are characteristic of major-grade lesions. First, there is a large intercapillary distance associated with a regular and coarse punctation pattern, with the dilated terminal vessels having a forked or antler-type appearance; this has been referred to as a double capillary pattern. Second, there is an irregular surface contour, seen by reference to the uneven response of the photographic flash; and third, a sharp border exists (arrowed). Figure 6.13 (a) This large lesion, which covers most of the ectocervix (1) and extends into the endocervix at (2), shows five major features characteristic of a high-grade precancerous lesion. First, the vascular pattern is a combination of mosaic and punctation. Clearly demarcated punctation vessels are seen toward the periphery of the lesion, while in the area extending into the endocervix (2) mosaic-type terminal vessels are seen (1). There is a combination of circular, polygonal, hairpin, and occasionally irregular vessels. Some are smoothly curved while others curve irregularly and occasionally there are intertwining strands of dilated capillaries of varying caliber. Like the punctation vessels, these mosaic vessels are observed in relatively distinct areas. Second, the intercapillary distance is increased and variable, signifying variation in the severity of the cervical intraepithelial neoplasia (CIN). Third, there is irregularity in the surface contour: the stereoscopic nature of colposcopy and the magnification have accentuated this feature. The native squamous epithelium at the periphery has a smooth surface, while the CIN lesion, which occupies the whole of the transformation zone, has an uneven surface and is slightly raised compared with the surrounding epithelium. The variation in the flash reflection further accentuates this irregularity. Fourth, there is variation in color tone; this is obvious between the native squamous epithelium and the darker central CIN lesion. Fifth, there is a clear line of demarcation between the native squamous epithelium and the CIN lesion. (b) A combination of mosaic and punctation patterns exist in this high-grade CIN lesion. However, there is also some leukoplakia (1) present and one area has small plaques that occasionally coalesce to form larger ones. The outline of the area is irregular. Leukoplakia may hide the true nature of the underlying epithelium, although in this lesion the punctation, mosaic pattern, and atypical branching of the surrounding vessels make the lesion an obvious high-grade CIN or early invasive lesion. A sharp line of demarcation associated with the irregular surface contour and the difference in color tone in relation to the native squamous epithelium at (2) are other obvious features of the high-grade lesion. As has already been discussed, atypical vessels may indicate invasive cancer (Figure 6.7a–c). In the earlier stages of invasion it may be difficult for the colposcopist to note a clear distinction between the vascular patterns of CIN, namely punctation and mosaic, and these atypical vessels. In most instances high-grade CIN and early invasion are found together in the cervix, and only a small focus of slightly atypical vessels is seen in a more extensive area of an otherwise typical punctation and mosaic pattern. This is shown in Figure 6.14a. In this lesion not only is there a difference in color tone and a clear line of demarcation between the native squamous epithelium and the actual precancerous lesion (arrowed), but also there are variations within the vessel characteristics. At (1) there is a typical punctated appearance, signifying a high-grade lesion, but at (2) the mosaic pattern has changed to one of a coarse and irregular structure with extremely large intercapillary distances between the vessels. There is also an avascular-type whiteness appearing within the epithelium. All these features indicate early invasion. In area (3) the smoother mosaic pattern still exists and there is a reduction in the intercapillary distance compared with the area of early invasion at (2). During the initial development of atypical vessels in areas of typical mosaic and punctation patterns there may be a reduction in the intercapillary distance. However, as the malignant cells proliferate, so large avascular areas, signified by an increased intercapillary distance, develop. This is clearly seen in Figure 6.14b, where the typical punctate pattern has been disrupted by the developing atypical capillary loops, which run parallel with the surface into the field of punctation, and where there has been an initial reduction in the intercapillary distance. When an adenocarcinoma or an anaplastic carcinoma develops it frequently demonstrates a vascular pattern that differs from that of the squamous lesions described so far. The adenocarcinomas seem to derive their nutrition through the central capillary system; this is in contrast to the well-differentiated squamous cell cancers that seem to have a microcirculation characterized by peripheral vessels that surround the epithelial buds but do not seem to have any penetrating vessels. The undifferentiated lesions tend to have fine capillaries penetrating between the epithelial buds of malignant cells. Therefore, the intercapillary distance in these undifferentiated malignancies may be quite normal in many areas. An example of such an early adenomatous malignancy is seen in Figure 6.14c, where the papillary nature of the columnar epithelium can still be seen with atypical vessels present. The sharp demarcation (arrowed) between the native squamous and the abnormal capillary structures is obvious. There would seem to be a correlation between definite vascular patterns and the early stages of adenocarcinoma. These are seen diagrammatically in Figure 6.15a. The upper six vessels outlined are present in non-malignant squamous lesions, while the lower seven (including Figure 6.15b) exist in squamous malignancy. However, in the case of adenocarcinoma, there may be a mixture of both types. As will be seen later in this chapter, there would seem to be specific types associated with the corresponding colposcopically recognized adenocarcinomatous change. It would likewise appear that while mosaic and punctation changes are found in squamous epithelium, they would seem never to be present in adenocarcinomas. However, they are found in some adenosquamous lesions. Figure 6.15 (a) Different vascular patterns (adapted from Ueki, 1985). The most common vascular pattern in cases of adenocarcinoma is that of the root-like vessels. In these early stages only one or two such vessels are noted, but in the more advanced stages they are more numerous. Thread-like vessels (Figure 6.15a,b) may also be seen, while in advanced cases tendril-like vessels increase in conjunction with willow-branch vessels. Corkscrew vessels seem never to be present in adenocarcinomatous lesions. Further description of adenocarcinomas is given in section 6.14. The classification is based on the fact that most cervical intraepithelial lesions arise within the transformation zone. The classification also recognizes that there are frequently abnormal colposcopic appearances, all attributed to HPV, that occur within the original squamous epithelium. These lesions have little or no neoplastic potential and were generally described as subclinical papillomavirus infection (SPI) in the past. However, it was felt that it was no longer appropriate to describe all abnormal (atypical) colposcopic appearances as representing images present within the broad category of the atypical transformation zone. The words “atypical” and “abnormal” have been used in many classifications. Indeed, “abnormal” is used in the International Federation of Cervical Pathology and Colposcopy (IFCPC) classification. In Spanish, and to a lesser extent in German, the word “atypical” has serious connotations, while the word “abnormal” in these languages is too close to “normal.” The IFCPC classification, which has recently been altered and upgraded, is presented in Table 6.1. Mention is given below to the new nomenclature and is inserted beside the former terms. Table 6.1 (a) Colposcopic terminology of the cervix by the International Federation of Cervical Pathology and Colposcopy 2011 Table 6.1 (b) Clinical and colposcopic terminology of the vagina by the International Federation of Cervical Pathology and Colposcopy 2011 The most important part of the examination of the abnormal (atypical) colposcopic epithelium is to obtain a clear view of the full topography and morphology of the lesion (Figure 6.1). The topography involves determining the outer and inner limits of the abnormal (atypical) region, while the morphology involves making a precise examination of all the features detailed in the previous section, such as vascular pattern, intercapillary distance, surface contour, color tone, and clarity of demarcation. The assessment of the inner limit is one of the most important parts of the examination because it will allow distinction to be made between a satisfactory and an unsatisfactory colposcopy. A satisfactory colposcopic examination is defined as one in which the new squamocolumnar junction and the full extent of abnormal (atypical) epithelium is visible. An unsatisfactory examination is one in which the new squamocolumnar junction is not visible (Figures 6.16–6.19), or where severe inflammation or severe atrophy make it impossible for the examiner to determine the upper limits of the lesions. The limits are clearly defined by the new squamocolumnar junction and it signifies the upper extent of the abnormal (atypical) epithelium within the endocervical canal. An example of this can be seen in the histologic specimen in Figure 6.20; this specimen has resulted from a loop excision of an ecto- and endocervical lesion. The ectocervical part of the lesion is present between points (1) and (2), while the endocervical limits extend from (2) to (3) with the new squamocolumnar junction in the region of (3). The lesion itself is a high-grade intraepithelial lesion (CIN3) and extends deep into the glands of the endocervix. The area between (2) and (3), situated high in the endocervical canal, would most likely have been associated with an unsatisfactory colposcopic picture. Figure 6.16 A satisfactory colposcopic picture has been obtained for the posterior lip with the original columnar epithelium at (1), the new squamocolumnar junction at (2), and the original squamocolumnar junction at (3). On the anterior lip, the upper limit of the lesion is not so clearly seen as on the posterior lip, and it seems to be hidden behind some mucus. Until this mucus is removed, the nature of the epithelium on the anterior lip cannot be determined, and this constitutes an unsatisfactory picture. Figure 6.19 Dense acetowhite epithelium (1), the upper limit of which cannot be seen within the endocervical canal (arrowed). This constitutes an unsatisfactory colposcopic picture. The lateral limit of the lesion is at (2). The great variability shown in precancerous and cancerous changes is such that no single appearance can be called characteristic. The admixture of the variable blood vessel patterns with varying degrees of epithelial maturity associated with alterations in surface contour, color, and demarcation all determine the great variability in the resulting image. A number of grading systems have been devised to increase the objectivity of colposcopic grading and reduce the inter- and intraobserver variability. This provides a less subjective approach to the differentiation between low- and high-grade colposcopic changes. One such system is suggested by Coppleson and Pixley. The scheme employs a practical subdivision of the appearances into those that are insignificant (grade 1), significant (grade 2), and highly significant (grade 3). In grade 1, the lesions show minimal neoplastic potential and invasion is likely to be years away, if it ever occurs; grade 2 comprises lesions that have a neoplastic potential but where invasion is not imminent; and grade 3 covers those lesions that have a high neoplastic potential and where invasion is imminent. Definitions of the grades are as follows. Figure 6.21 A grade 1 insignificant lesion with acetowhite shiny epithelium (2) extending into the endocervix (1). The upper limit of the lesion is arrowed. The indistinct borders at (3), the shiny acetowhite epithelium, and the fine-caliber vessels with a small intercapillary distance (4) are characteristic of these minor lesions. Figure 6.22 A mixture of grade 1 (insignificant) and grade 2 (significant) lesions. The area at (1) is a grade 1 area with shiny acetowhite epithelium, indistinct borders, and very-fine-caliber vessels. In comparison, area (2) shows a grade 2 area with sharper borders, regularly shaped vessels, and an increased intercapillary distance. This abnormal (atypical) epithelium extends into the endocervical canal (3) and is arrowed. The overall colposcopic image is unsatisfactory. Figure 6.23 A grade 2 significant lesion with the acetowhite epithelium showing greater opacity, dilated-caliber, regularly shaped vessels, and an increased intercapillary distance. There are gland openings with a thickened white epithelium. The overall colposcopic image is unsatisfactory and the abnormal (atypical) epithelium (arrowed) extends out of view into the endocervix (1). Figure 6.24 A grade 3 (highly significant, highly suspicious) lesion with very white or gray opaque epithelium (1) extending into the endocervical canal (2, arrowed). Occasional atypical vessels are present on the posterior lip (3) and there are gland openings with thickened white epithelium at (4). This latter appearance is referred to as gland cuffing and represents an extension of the cervical intraepithelial neoplasia process into the subepithelial glandular crypts. Figure 6.25 (a) A grade 3 (highly significant, highly suspicious) lesion with very white or gray opaque epithelium (2) extending out of view into the endocervix (1, and arrowed). The sharp original squamocolumnar junction is at (3). This is an unsatisfactory colposcopic image. (b) A grade 3 (highly significant, highly suspicious) lesion with very white or gray opaque epithelium (2) extending out of view into the endocervix (1, and arrowed). There is a sharp border (3) with atypical vessels present at (4); these give a distinctive color-tone difference between the atypical transformation zone and the original squamous epithelium. On the posterior lip (5) there is an outer area with an indistinct border and no atypical vessels are present. (c) A grade 2 (significant, suspicious) lesion extending across the ectocervix. The acetowhite epithelium has variable degrees of opacity. The area surrounding (1) is of a translucent acetowhite epithelium with irregular feathery margins consistent with a diagnosis of human papillomavirus (HPV)/low-grade epithelial atypia. The area surrounding (2) on the posterior lip has an obvious sharper, well-defined margin (arrowed) and the acetowhiteness is of a greater opacity than that seen on the anterior lip. There are no obvious vascular changes. These changes at (2) are consistent with a high-grade epithelial lesion (grade 2). When grading is undertaken using the Reid–Coppleson colposcopic index, a score of 5 is obtained, made up as follows: 2 points are given for color, 2 for margins and surface configuration (there is an area of internal demarcation), and 1 point for vessels (absent vascular patterns). Note that further points would have been given but no iodine staining is available. However, the final score of 5 puts the lesion into the high-grade squamous intraepithelial lesion category. (d) A lesion showing both low and high grades of abnormality. On the anterior lip, the predominant epithelium around (1) is of a low-intensity acetowhitening which is not completely opaque. The lesion margins are feathered or finely scalloped at (2) and a poorly formed mosaic pattern predominates through the outer half of the acetowhite epithelium (3). The arrows mark an internal margin enclosing a raised higher intensity acetowhite area. This is seen at (4) on the anterior lip and a similar area is present at (5) on the posterior lip. Using the Reid–Coppleson colposcopic index, the color of the lesion (at the denser central acetowhite area) scores 1 point. The margins and surface configuration score 2 in view the presence of an internal margin. One point is given in the central area where there are absent vessels. It was not possible to stain with iodine but it is most likely that it would have scored at least 1 or possibly 2, giving a total of 5 or 6, making it a high-grade lesion. Loop excision showed this area to be composed of cervical intraepithelial neoplasia (CIN) 1 and CIN2. (e) This photograph shows a wide area of low-intensity acetowhitening, not completely opaque at (1) with irregular margins and a central “raised” area (2) on the anterior lip. The color is accentuated by the flash photography but a higher power view in Figure 6.25f reveals this area as having a micropapillary surface configuration (1). Peripheral to this in Figure 6.25f there is an area of poorly defined fine mosaic consistent with subclinical papillomavirus infection. Using the Reid–Coppleson colposcopic index, 0 points would be allocated for color, 0 points for the lesion margin and the surface configuration, and 0 points for vessels. Iodine staining was not available but, even so, the lesion is unlikely to score more than 1 point in total, making it a low-grade squamous intraepithelial lesion or HPV/atypia. This lesion, although spectacular in appearance, was associated with a very benign epithelial change. This shows the utility of the Reid–Coppleson colposcopic index. In grade 1 the histologic features can be: (i) those of metaplastic epithelium (immature, mature, or acanthotic epithelium); (ii) an SPI; or (iii) CIN1. In grade 2 the lesions usually correspond to those of CIN2–3. In grade 3, CIN3 or early invasion can be anticipated. Examples of the various grades of lesion can be seen in Figures 6.21–6.25. In other classifications it would be assumed that the grade 1 of Coppleson and Pixley’s classification corresponds to the so-called minor- or low-grade lesions, while grades 2 and 3 correspond to major- or high-grade lesion. The Reid colposcopic index was published in 1993. It is the most widely used scoring system and was designed to standardize colposcopic examination and to improve prediction of histologic diagnosis. However, using the Reid index in the ALTS failed to detect CIN2 or higher at levels expected. The following description has been modified from Reid’s original description by Professor Malcolm Coppleson in collaboration with Dr Richard Reid. This takes into account four colposcopic appearances: (i) color; (ii) lesion margin and surface configuration; (iii) vessels; and (iv) iodine staining. These four colposcopic signs are assigned points ranging from 0 to 2 (Table 6.2). The results are then added to derive an overall colposcopic index that predicts the histologic diagnosis, as shown in Table 6.3. Examples of the usage of this classification in practice are shown in Figure 6.25e. Table 6.2 The modified Reid colposcopic index* *Colposcopic grading performed with 5% aqueous acetic acid and 1% iodine solution. †Microexophytic surface contour indicative of colposcopically overt cancer is not included in the scheme. ‡Epithelial edges tend to detach from underlying stroma and curl back on themselves. Note: prominent minor-grade lesions are often overinterpreted and subtle avascular patches of high-grade squamous intraepithelial lesion can easily be overlooked. §Score zero even if part of the peripheral margin does have a straight course. ¶At times, mosaic patterns containing central vessels are characteristic of low-grade histologic abnormalities. These minor-grade lesion capillary patterns can be quite pronounced. Until the physician can differentiate these fine from coarse vascular patterns, overdiagnosis is the rule. **Branching atypical vessels indicative of colposcopically overt cancer are not included in the scheme. ††Generally, the more microcondylomatous the lesion, the lower the score. However, cancer can also present as a condyloma although this is a rare occurrence. ‡‡Parakeratosis: a superficial zone of cornified cells with retained nuclei. Table 6.3 Colposcopic prediction of histologic diagnosis using the Reid colposcopic index (RCI) *Three points likely to equate with low-grade squamous intraepithelial lesion (LSIL); 4 points with high-grade squamous intraepithelial lesion (HSIL). HPV, human papillomavirus. Table 6.4 Swede scoring model Strander et al. from Sweden proposed a new scoring system in 2005. The ‘Swede score’ is a modification of the Reid scoring system. It is simple to use, with no major learning curve. The Swede scoring model includes lesion size as a variable in addition to the four original variables described in the Reid colposcopic index. The Swede score also redefined the remaining variables of Reid’s score. Recent evaluation of the Swede scoring system in a UK setting showed that a score of 8 or more had a sensitivity, specificity, and positive and negative predictive values of 38%, 95%, 83%, and 70%, respectively, for lesions in which the final diagnosis was CIN2 or higher; it was also found that there was no obvious learning curve, and trainees showed comparable results to their trained colleagues. In the new classification (Table 6.1) there are listed two grades of abnormality as follows: The size of the abnormal epithelium as judged by the number of quadrants involved or the percentage of the cervical area occupied. Abnormal (atypical) epithelium extending high into the endocervix presents a problem to the clinician. If its upper limit can be seen the colposcopy is deemed to be satisfactory or adequate; if not then it is unsatisfactory, although in the new IFCPC terminology it can be described as being partially visible or not visible. In this textbook, we followed the previous classification to describe unsatisfactory colposcopy. Very often the upper limit can be clearly defined by using simple examination methods. Once the upper limit has been found, the clinician can be satisfied that no further areas of precancerous or cancerous tissue exist above that line. This applies only to squamous lesions because abnormal glandular changes may well exist higher. The clinician will be alerted to the fact that such glandular changes exist by finding abnormal (glandular) cytology. The simplest method of defining the upper limit of the lesion is to use a small cotton-tip bud. In Figure 6.26 such an examination is under way. An area of atypical epithelium (3) extends into the endocervix (1). The upper limit (2) can be clearly seen and has been brought into view by pressure of the cotton-tip bud (4) on the posterior lip of the cervix. In Figures 6.27 and 6.28 a previous laceration in the cervix has produced an unsatisfactory colposcopic picture. An area of very mild acetowhite epithelium (2), whose outer limit is at (3), seems to extend into the endocervix. This patient presented with mild dyskaryotic smears (Bethesda LSIL). In Figure 6.28, two cotton-tip swabs have been used to separate the lateral lips of the deformed cervix, and the upper limit within the endocervix can be clearly seen at (1). In Figures 6.29–6.31 the area of grade 2 abnormal (atypical) epithelium is seen at (2) and its extension into the endocervix is at (1). In Figure 6.29 it is also marked with an arrow. The outer limit of the lesion is at (3). In Figure 6.30 the cervix has been opened with a pair of Desjardins’ (gall bladder) forceps. The upper limit, represented by the new squamocolumnar junction, comes into view on the anterior lip at (1), but is not completely visible on the posterior lip until the forceps have been further opened (Figure 6.31). At this stage a small area of acetowhite epithelium is visible at the 6 o’clock position, just inside the endocervix. This view in Figure 6.31 represents a satisfactory colposcopic image. However, the lesion does extend into the lower endocervical canal and this must be taken into consideration when treatment is given. The diagrams opposite Figures 6.29–6.31 more clearly demonstrate, by virtue of using the Desjardins’ forceps, the upper limits (arrowed) of the abnormal (atypical) epithelium as delineated by the new squamocolumnar junction within the endocervical canal. The usefulness of the Desjardins’ forceps is further seen in Figures 6.32–6.35 and the accompanying traces. Figure 6.32 The upper blade of the Desjardins’ forceps (3) has been used to outline clearly the upper extent (new squamocolumnar junction) of the abnormal (atypical) epithelium (2) within the endocervical canal; this can be seen as a sharp line (1) and is arrowed. The lesion is of grade 1, and biopsy revealed the presence of cervical intraepithelial neoplasia 1 with human papillomavirus changes. Figure 6.35 (a) Endocervical acetowhite epithelium (minor grade) (2), histologically composed of immature metaplastic epithelium, whose upper limit is at (1) (arrowed). Cervical smears on three occasions showed mild dyskaryosis (Bethesda low-grade squamous intraepithelial lesion). (b) A cervicoscope inserted within the endocervical canal, with saline irrigation at 20–30°C, showed altered white papillae (1) that, when stained with acetic acid, appeared very white and suspect, and in conjunction with abnormal glandular cytology demanded biopsy which revealed early papillary adenocarcinoma. (c) Cervicoscopy revealed a small focal patch of endocervical (2) acetowhite epithelium (grade 3) with an area of low-grade epithelium (1) that extends from the ectocervix. (d) Cervicoscopy shows an endocervical yellow nodular growth with atypical vessels (root-like and willow-branch capillaries, Ueki (1985)) which histologically revealed a poorly differentiated tubular adenocarcinoma. This case demonstrates the value of endocervical cervicoscopy in patients with abnormal glandular cytology with no obvious ectocervical lesion. The follow-up of patients treated for precancerous cervical disease is most important (Figures 6.36–6.40). With all the techniques employed, be they excisional or local destructive, there is always the risk of some constriction of the ecto- and endocervix. This constriction may range from complete stenosis to the inability to allow passage of the normal devices used to harvest endocervical cells in follow-up surveillance. Figure 6.36 A small area of abnormal (atypical) grade 1 epithelium exists at (2), and the upper limit, the new squamocolumnar junction, is seen at (1, arrow) after the introduction of Kogan’s endocervical forceps. This residual epithelium is all that remains from a previous high-grade lesion that had been treated with cryotherapy some 9 months earlier. Figure 6.39 The cervix of a woman treated some 12 months earlier with laser cone biopsy for a cervical intraepithelial neoplasia 3. The external os is constricted and will just about allow the passage of an endocervical brush appliance for cytologic purposes. Local anesthetic may need to be inserted around the external os, and tenaculum forceps applied to the anterior lip to provide countertraction when the device is gently but firmly inserted into the endocervical canal. It is important to insert the anesthetic needle into the posterior part of the cervix and also well lateral to the external os. If this is not done, then blood from the injection site may flow back into the endocervix and thereby contaminate the cytologic specimen. Figure 6.40 The cervix some 18 months after diathermy coagulation for a major-grade lesion. This cervix has constricted to a narrow transverse opening. It could not be dilated with either Desjardins’ or Kogan’s forceps when cervical dilatation was necessary to procure an endocervical sample. The tail of an intrauterine device can be clearly seen. The use of an endocervical dilator (as shown in Figure 7.77b) will be helpful. The projection of the abnormal (atypical) epithelium within the endocervix can be followed using the devices previously mentioned, such as the cotton-tip swab or Desjardins’ (gall bladder) forceps. Kogan’s endocervical forceps, used extensively in the USA, may also be used and these are shown in Figure 6.36. Other techniques that may be used to ensure opening of the constricted endocervix to obtain an adequate smear include the insertion of a hydroscopic device which can be removed after 24 hours. The only problem with this device is that its removal may well cause abrasion of the endocervical epithelium and so produce bleeding; this leads to difficulty not only in obtaining but also in interpreting the endocervical smear. The administration of estrogens, especially to postmenopausal females, will ensure some softening and possibly dilatation of the constricted endocervical canal However, if an excessive amount of scar tissue exists, then it may be difficult for exogenous estrogens to produce any effective dilatation. In some instances it may be necessary to insert a local anesthetic into the cervix so that an endocervical cytologic brush appliance can be forcibly introduced into a very stenosed external cervical os. The cervices seen in Figures 6.39 and 6.40 would represent such a case. A biopsy of the abnormal (atypical) epithelium of the cervix is imperative if local destructive treatment of CIN is contemplated. Such treatment usually consists of either cryotherapy, deep radial diathermy, laser evaporation, or cold coagulation and should be confined to cases in which there is no suggestion of invasion either colposcopically or histologically. The colposcopic biopsy and its assessment by an experienced pathologist is an important procedure to be carried out before any further treatment is undertaken. It should be noted, however, that colposcopic punch biopsy does not always resolve the subjective difficulties with colposcopy. It has a false-negative rate of between 41% and 54%, and in addition may miss glandular abnormalities (Figure 6.121). The biopsy site is selected from the area with the most severe degree of abnormality. It is the authors’ policy to take multiple biopsies under a suitable local anesthetic block administered with a dental syringe. The forceps used vary in shape and efficiency, but with some it is very difficult to obtain a biopsy from a site where the epithelium is on a particularly curved surface of one of the cervical lips (Figures 6.41, 6.42). It may be necessary to use an Iris hook or tenaculum to steady the tissue while the biopsy is being taken. Some of biopsy forceps have a toothed jaw which facilitates better application to the tissue. Figure 6.41 Eppendorfer forceps with a rotating 25 cm shaft (1) are being used to biopsy an area of abnormal (atypical) epithelium (2) on the anterior cervical lip. Figure 6.42 Photograph of a 5 mm forceps biopsy (from the case shown in Figure 6.41) orientated on filter paper with the epithelial surface uppermost. After the biopsy has been taken, the bleeding can be stopped by the use of astringent agents. Monsel’s solution (ferric subsulfate) can be placed immediately on the area, or a more simple procedure is to apply a silver nitrate stick immediately. The stick should be left in place for at least 1–2 minutes and can then be removed. A small diathermy loop has been developed to obtain samples of abnormal tissue. This was popularized in Paris by Dr Rene Cartier nearly 20 years ago and is shown in Figures 6.43 and 6.44. Figure 6.43 A small diathermy loop biopsy device (1), developed by Dr Rene Cartier, is used to take a biopsy from minor-grade abnormal (atypical) epithelium at (2). Figure 6.44 The biopsy loop (1) shown in Figure 6.43 has now taken a small area of tissue (2). The defect that extends from the endocervical canal to the outer limit of the lesion can be seen at (3). Small gland openings are visible in the depth of the defect toward the endocervical margin. An extremely satisfactory sample can be obtained by this method.
Diagnosis of cervical precancer: Use of colposcopy
6.1 Introduction
6.2 Which cytologic abnormalities need further investigation?
6.3 Colposcopy: the initial clinical examination
6.4 The rationale for the use of colposcopy in the diagnosis of cervical precancer
6.5 Colposcopic appearance of the abnormal (atypical) cervical epithelium
Morphology of the abnormal (atypical) epithelium
The effect of acetic acid and iodine
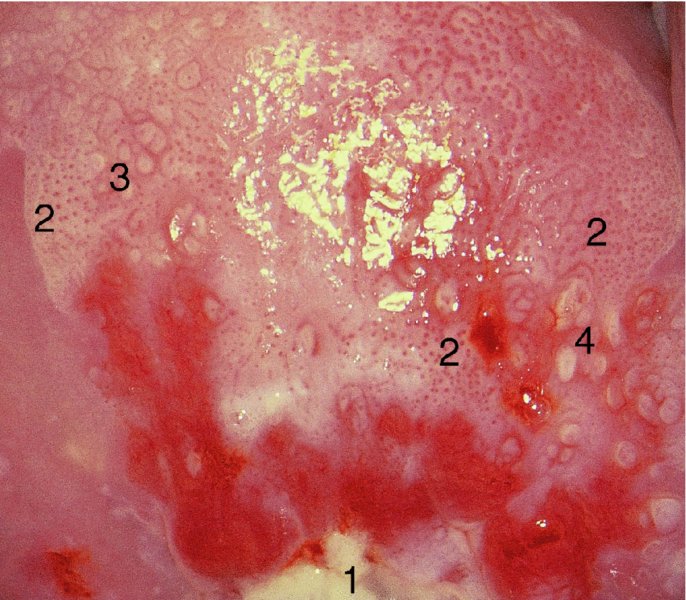
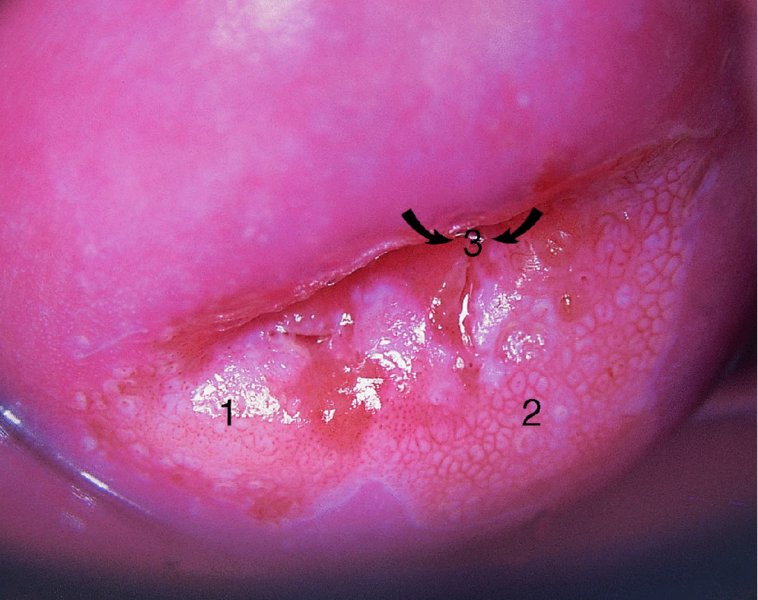
Margins
The effect of surface contour
Vascular patterns
Punctation and mosaic
Formation of punctation and mosaic
Atypical vessels
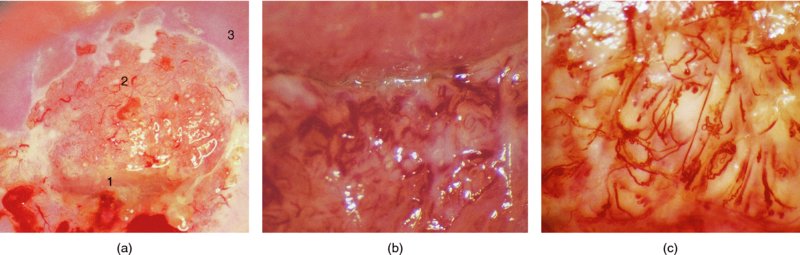
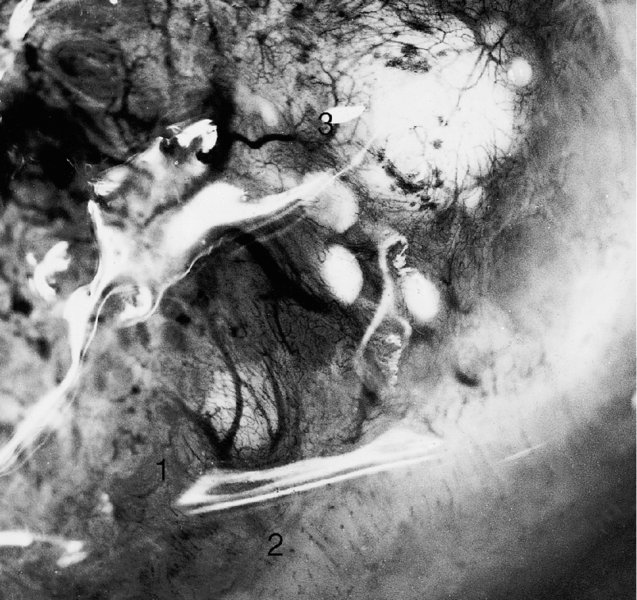
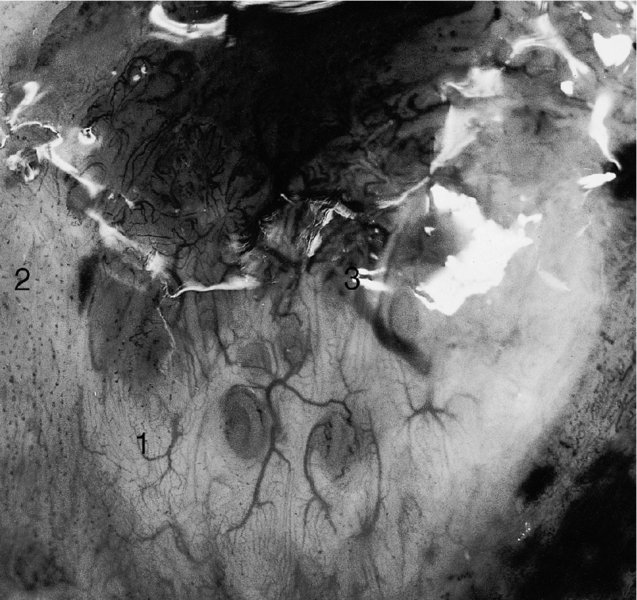
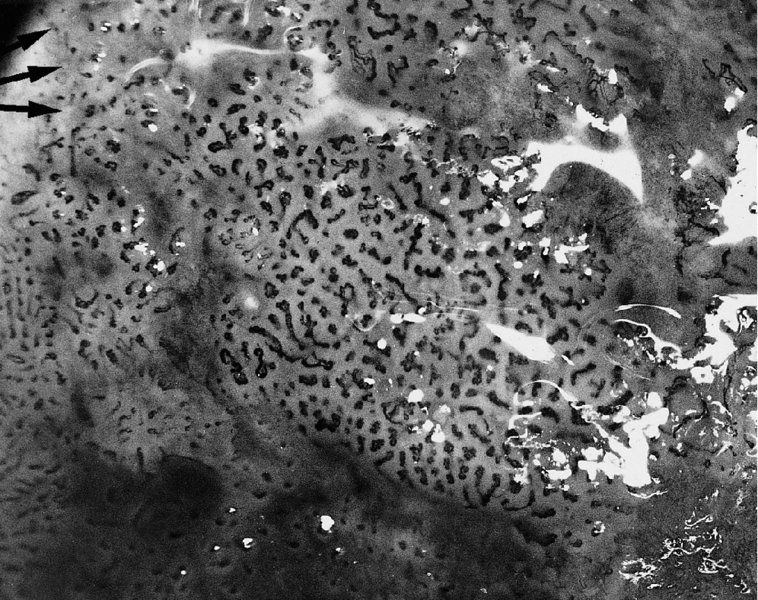
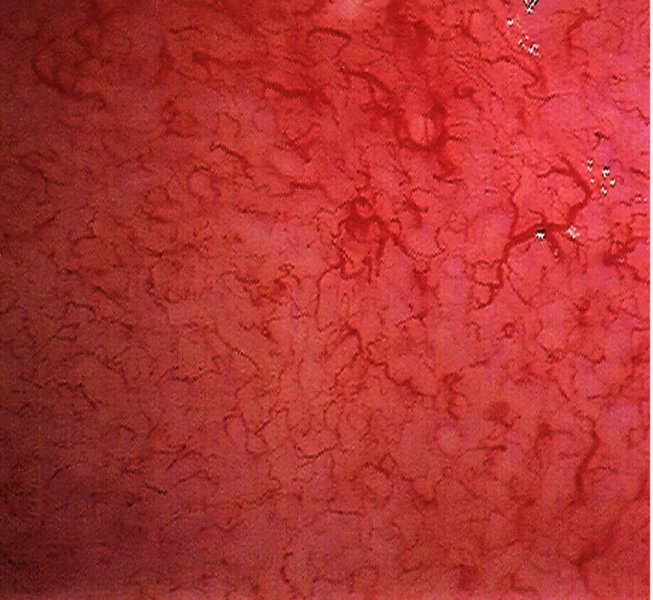
Figure 6.8 and 6.9 Saline colposcopy has been used to highlight the three types of vessel seen in the normal cervix. A dense and fairly regular meshwork of very fine capillaries, described as coiled network capillaries, is seen at (1) in both photographs. The second type, the so-called hairpin capillaries, are characterized by one ascending and one descending branch of a very-fine-caliber vessel; these course together and form a small loop. They sometimes give the appearance of a fine and regular punctate pattern, as seen at (2) in both photographs. The third type, occurring predominantly in the transformation zone, is composed of terminal vessels that are seen running parallel with the surface and branching in a tree-like manner. These are called branched vessels and are shown at (3) in both photographs. Branched vessels divide dichotomously and ultimately lead into a fine network of capillaries with normal intercapillary distances.
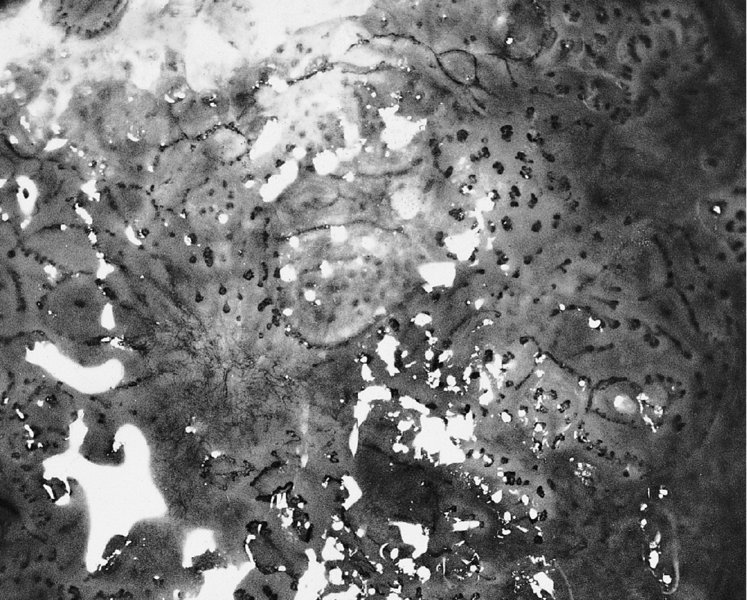
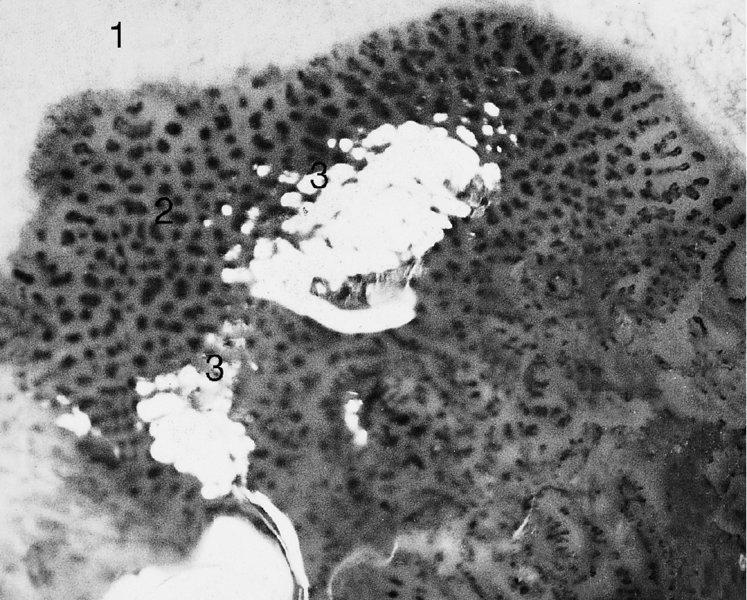
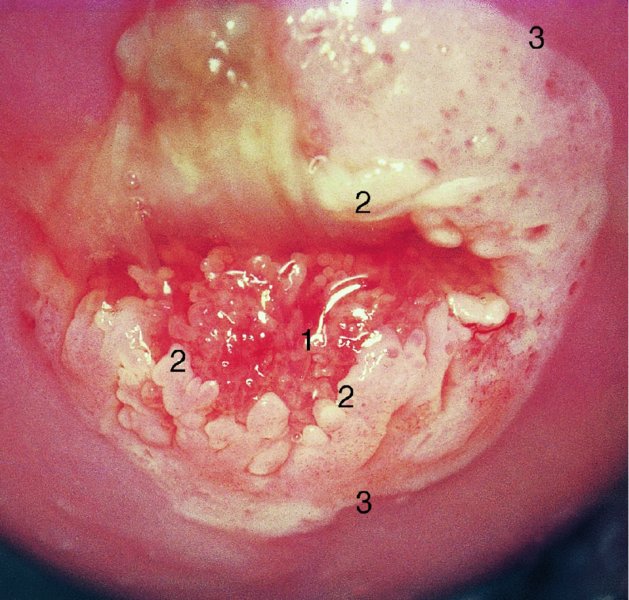
The vascular pattern of early invasion


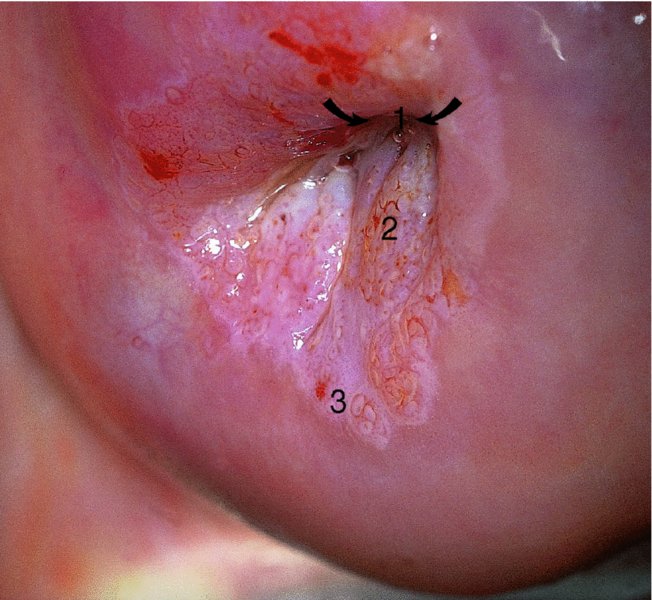
6.6 The classification of colposcopically abnormal (atypical) cervical epithelium
Section
Pattern
General assessment
Adequate or inadequate for the reason (e.g., cervix obscured by inflammation, bleeding, scar)
Squamocolumnar junction visibility: completely visible, partially visible, not visible
Transformation zone types 1, 2, 3
Normal colposcopic findings
Original squamous epithelium: mature, atrophic
Columnar epithelium: ectopy/ectropion
Metaplastic squamous epithelium; nabothian cysts; crypt (gland) openings
Deciduous in pregnancy
Abnormal colposcopic findings
General principles:
Location of the lesion: inside or outside the transformation zone; location of the lesion by clock position
Size of the lesion: number of cervical quadrants the lesion covers
Size of the lesion as percentage of the cervix
Grade 1 (minor): fine mosaic; fine punctation; thin acetowhite epithelium; irregular, geographic border
Grade 2 (major): sharp border; inner border sign; ridge sign; dense acetowhite epithelium; coarse mosaic; coarse punctation; rapid appearance of acetowhitening; cuffed crypt (gland) openings
Non-specific: leukoplakia (keratosis, hyperkeratosis); erosion
Suspicious for invasion
Lugol’s staining (Schiller’s test): stained or non-stained
Atypical vessels
Miscellaneous findings
Additional signs: fragile vessels; irregular surface; exophytic lesion; necrosis; ulceration (necrotic); tumor or gross neoplasm
Congenital transformation zone; condyloma; polyp (ectocervical or endocervical); inflammation; stenosis; congenital anomaly; post-treatment consequence; endometriosis
Section
Pattern
General assessment
Adequate or inadequate for the reason (e.g., inflammation, bleeding, scar) transformation zone
Normal colposcopic findings
Squamous epithelium: mature or atrophic
Abnormal colposcopic findings
General principles:
Upper third or lower two-thirds
Anterior, posterior, or lateral (right or left)
Grade 1 (minor): thin acetowhite epithelium; fine punctuation fine mosaic
Grade 2 (major): dense acetowhite epithelium; coarse punctuation coarse mosaic
Suspicious for invasion: atypical vessels
Additional signs: fragile vessels, irregular surface, exophytic lesion, necrosis ulceration (necrotic), tumor, or gross neoplasm
Non-specific: columnar epithelium (adenosis)
Lesion staining by Lugol’s solution (Schiller’s test): stained or non-stained; leukoplakia
Miscellaneous findings
Erosion (traumatic), condyloma, polyp, cyst, endometriosis, inflammation, vaginal stenosis, congenital transformation zone
6.7 Colposcopic examination of the precancerous/cancerous cervix
A satisfactory (adequate) or an unsatisfactory (inadequate) colposcopy
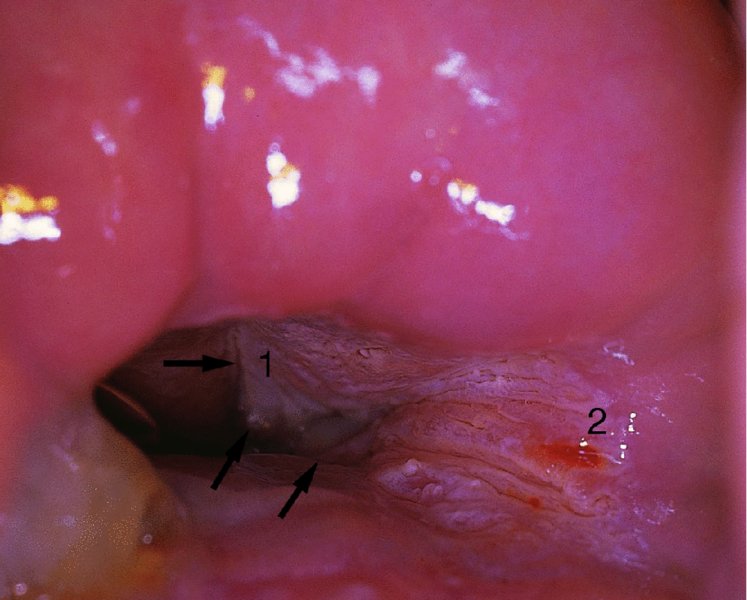
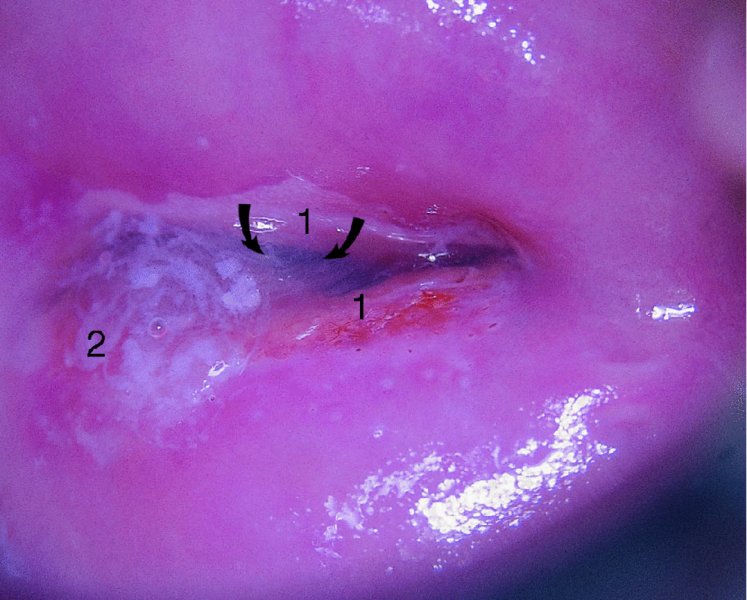
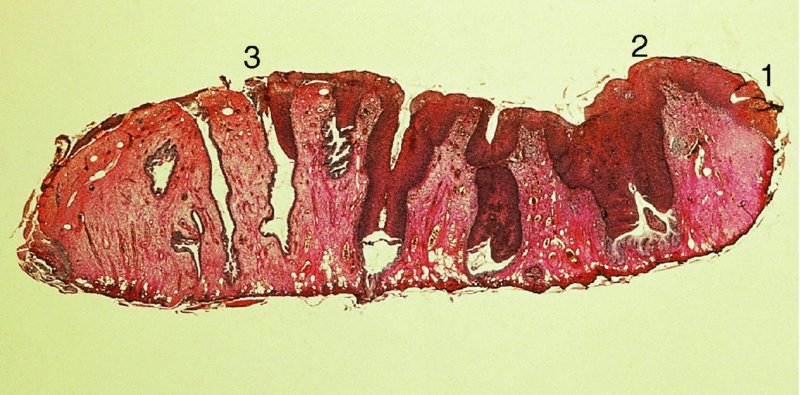
Grading of the abnormal (atypical) colposcopic findings
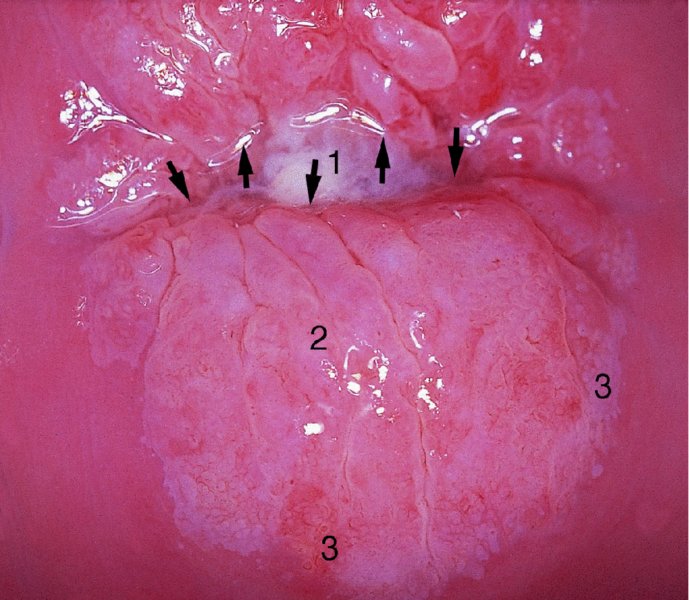
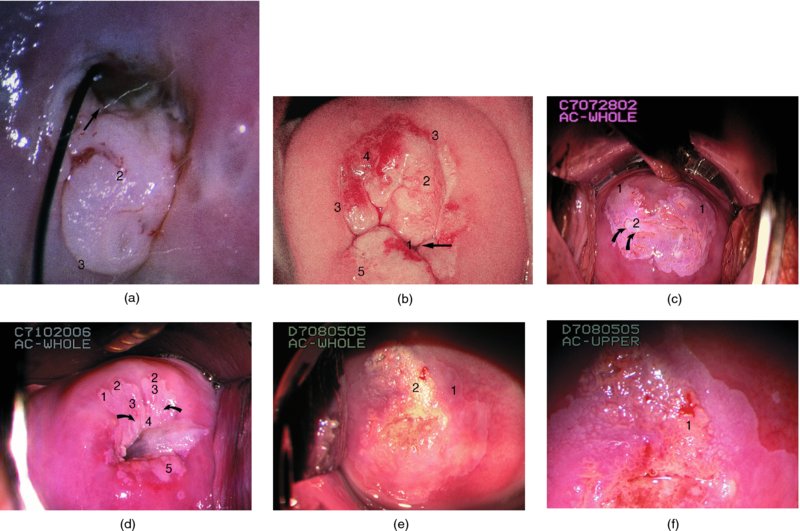
Reid colposcopic index
Colposcopic signs
Zero points
One point
Two points
Color
Low-intensity acetowhitening (not completely opaque); indistinct acetowhitening; transparent acetowhiteningAcetowhitening beyond the margin of the transformation zonePure snow-white color with intense surface shine (rare)
Intermediate shade—gray-white color and shiny surface (most lesions should be scored in this category)
Dull, oyster-whiteGray
Lesion margin and surface configuration
Microcondylomatous or micropapillary contour†Flat lesions with indistinct bordersFeathered or finely scalloped marginsAngular, jagged lesions§Satellite lesions beyond the margin of the transformation zone
Regularly shaped symmetrical lesions with smooth, straight outlines
Rolled, peeling edges‡Internal demarcations between areas of differing colposcopic appearance; a central area of high-grade change and peripheral area of low grade
Vessels
Fine/uniform caliber vessels¶Poorly formed patterns of fine punctation and/or mosaicVessels beyond the margin of the transformation zoneFine vessels within microcondylomatous or micropapillary lesions††
Absent vessels
Well-defined coarse punctation or mosaic, sharply demarcated**
Iodine staining
Positive iodine uptake giving mahogany brown colorNegative uptake of insignificant lesion, i.e., yellow staining by a lesion scoring 3 points or less on the first three criteriaAreas beyond the margin of the transformation zone, conspicuous on colposcopy, evident as iodine negative areas, such areas are frequently due to parakeratosis‡‡
Partial iodine uptake— variegated, speckled appearance
Negative iodine uptake of significant lesion, i.e., yellow staining by a lesion already scoring 4 points or more on the first three criteria
RCI (overall score)
Histology
0–2
LSIL–HPV/atypia
3–4
Overlap*
5–8
HSIL
Level A
Level B
Level C
Aceto-uptake
0 or transparent
Shady, milk
Distinct, stearin
Margins and surface
None or diffuse
Sharp but irregular, jagged, “geographical” Satellites
Sharp and even, difference in surface level including “cuffing”
Vessels
Fine, regular
Absent
Coarse or atypical vessels
Lesion size
<5 mm
5–15 mm or 2 quadrants
>15 mm or 3 or 4 quadrants or endocervically undefined
Iodine staining
Brown
Faintly or patchy yellow
Distinct yellow
Score
0
1
2
The Swede score (Table 6.4)
The new International Federation of Cervical Pathology and Colposcopy terminology (2011)
Unsatisfactory colposcopy: examination of the endocervical canal
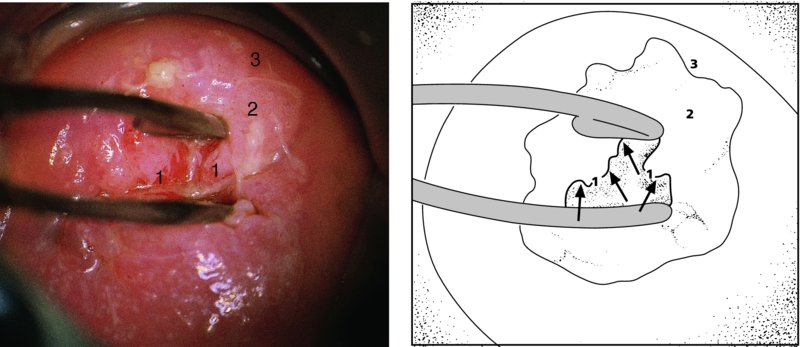
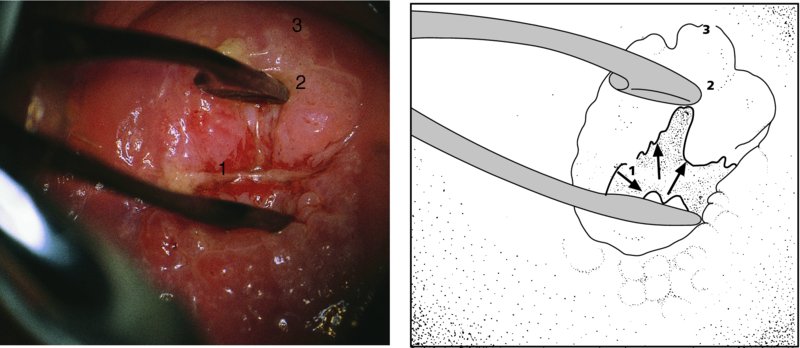
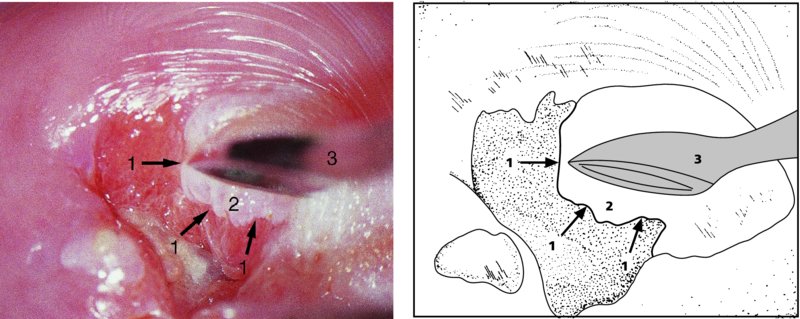
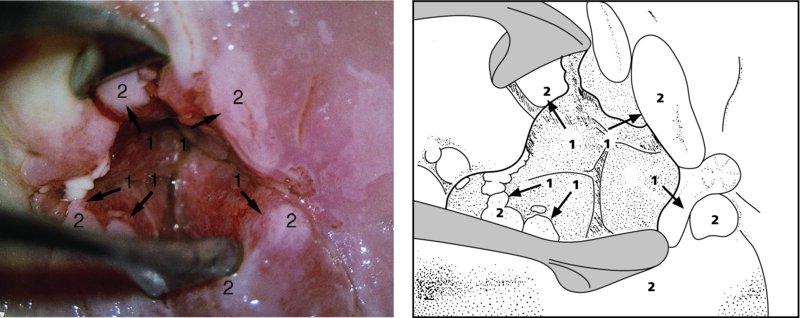
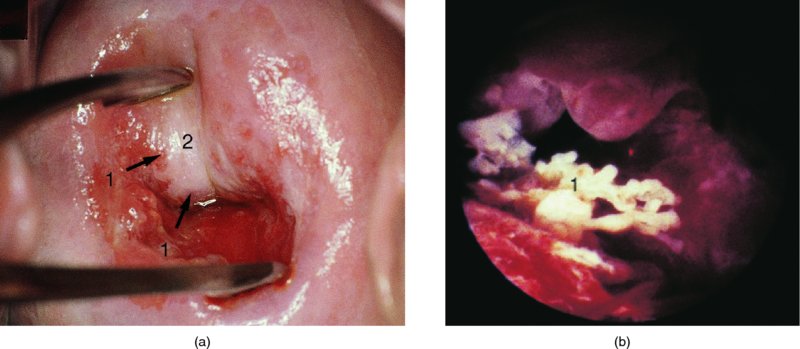
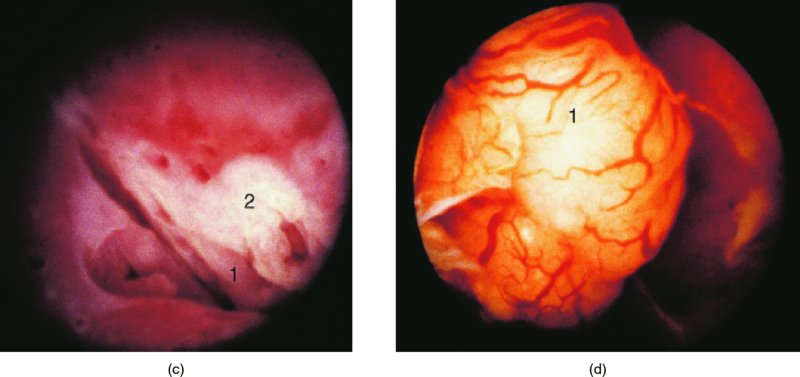
Further examination of the endocervical canal: after treatment of cervical precancer
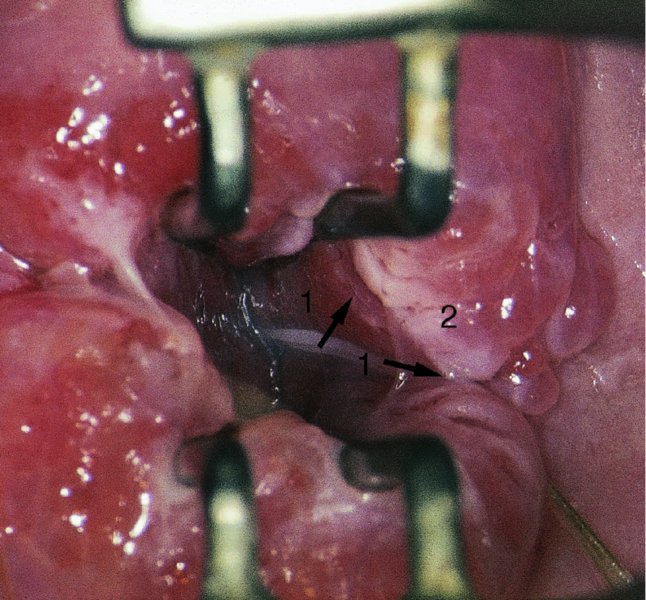
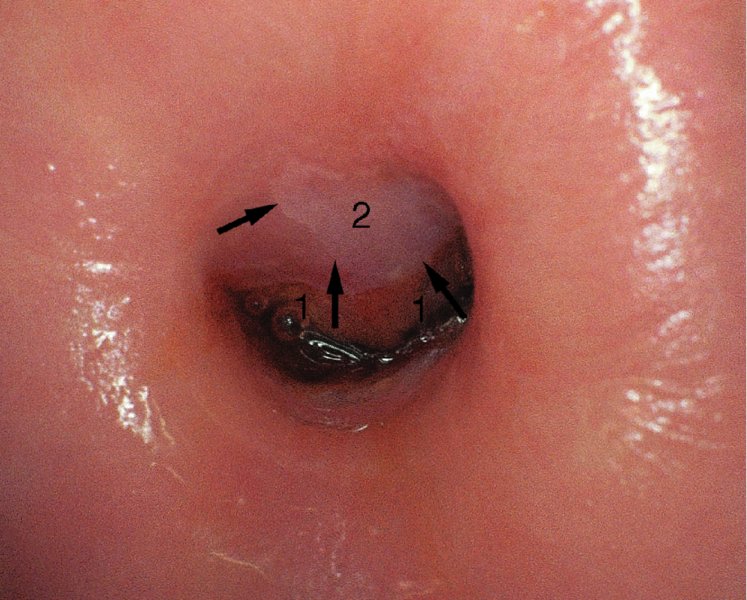
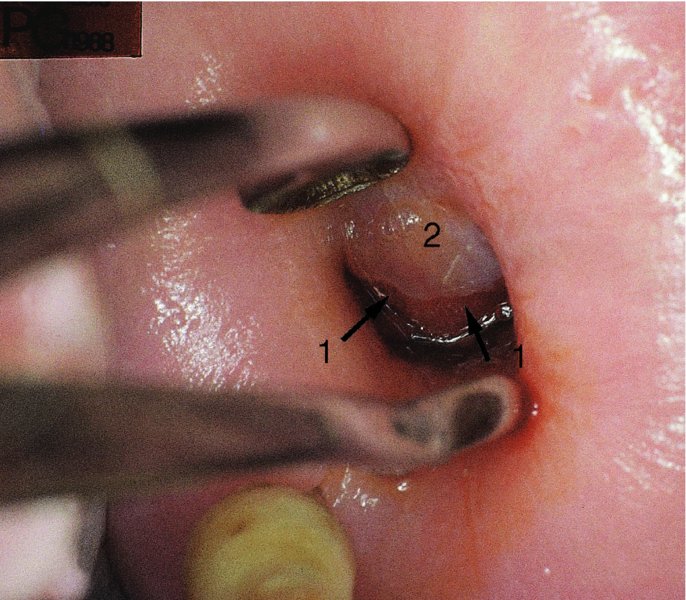
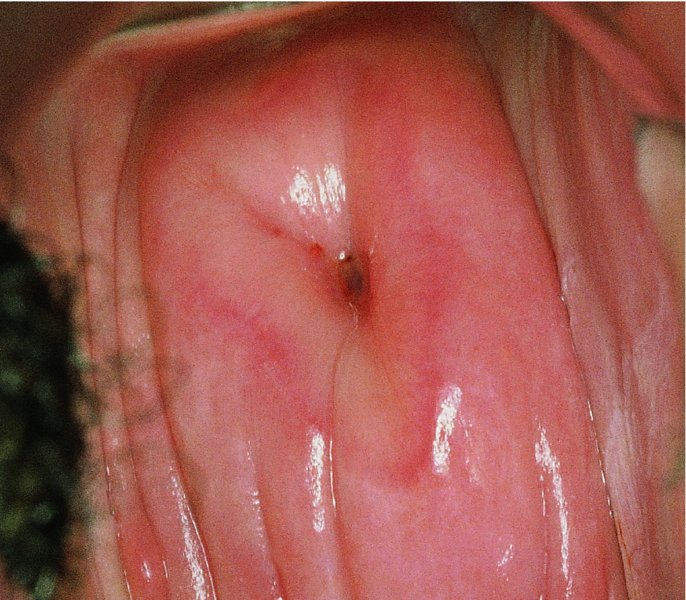
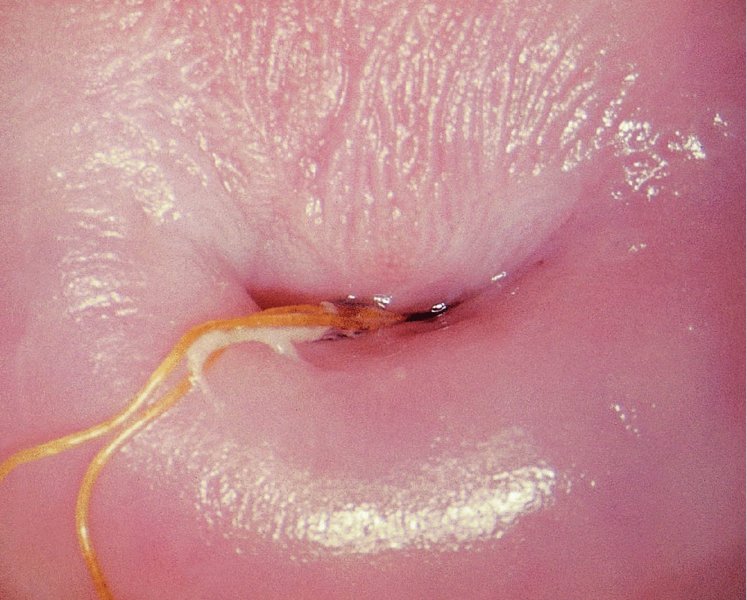
Colposcopic biopsy

Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


